본 내용은
https://bskyvision.com/644
https://hnsuk.tistory.com/31?category=958494
https://youtu.be/vRtM4K8e_Q4(고려대학교 산업경영공학부 DSBA 연구실)
참고하여 제작하였습니다.
CNN Algorithms 중에서 이미지 분류용 Algorithms 중 ResNet에 대해 포스팅해보겠습니다.
목차
CNN Algorithm - ResNet
ResNet 소개

이번 포스팅에서 알아볼 알고리즘은 ResNet입니다.
ResNet은 2015년 이미지넷 이미지 인식 대회(ILSVRC)에서 우승을 차지한 알고리즘입니다.
ResNet은 마이크로소프트에서 개발한 알고리즘입니다.
층수에 있어서 ResNet은 급속도로 깊어집니다. 2014년의 GoogLeNet이 22개의 층으로 구성된 것에 비해,
ResNet은 152개의 층을 갖습니다. 약 7배나 깊어졌습니다.
ResNet 연구팀은 이전 VGGNet이 밝힌 Layer가 깊어질수록 성능이 좋아지는 사실을 심층적으로 연구한 결과 Layer가 너무 깊어져도 성능이 떨어지는 현상을 확인합니다.
Layer가 깊어질수록 미분을 점점 많이 하기 때문에, Layer의 미분 값이 작아져 weight의 영향이 작아지는 Gradient Vanishing이 발생하여 Training Data로 학습이 되지 않는 문제가 발생합니다.
기존의 방식으로는 망을 무조건 깊게 한다고 능사가 아니라는 것을 확인한 것입니다.
뭔가 새로운 방법이 있어야 망을 깊게 만드는 효과를 볼 수 있다는 것을 ResNet의 저자들은 깨달았습니다.
그래서 ResNet 연구팀은 Skip Connection을 이용한 Residual Learning을 통해 Gradient Vanishing 문제를 해결합니다.
ResNet의 논문 이름은 "Deep Residual Learning for Image Recognition"으로, 논문제목의 Residual을 따서 ResNet이라고 부릅니다.
Residual Learning : Residual block
ResNet의 핵심인 Residual Block방식입니다.
위 그림에서 오른쪽이 Residual Block을 나타냅니다. 기존의 망과 차이가 있다면 입력값을 출력 값에 더해줄 수 있도록 지름길(shortcut)을 하나 만들어준 것뿐입니다.
기존의 신경망은 입력값 x를 타겟값 y로 매핑하는 함수 H(x)를 얻는 것이 목적이었습니다.
그러나 ResNet은 F(x) + x를 최소화하는 것을 목적으로 합니다.
ResNet은 최소 Gradient로 1은 갖도록 하기 위해, 미분 값 1을 갖는 입력값 x를 더해서 Gradient Vanishing 문제를 해결합니다.
ResNet의 original 논문에 의하면 경험적으로(empirically) 입력과 출력이 같아지도록 놓고 학습을 시켰더니 더 좋은 결과가 나왔다는 것입니다.
과정을 다시 한번 설명해보자면 입력값을 출력 값에 더해주기 위해서 지름길(Shortcut)을 추가합니다.
주의할 점으로 지름길(Shortcut)은 활성화 함수 이전에 시행됩니다.
x는 현시점에서 변할 수 없는 값이므로 F(x)를 0에 가깝게 만드는 것이 목적이 됩니다. F(x)가 0이 되면 출력과 입력이 모두 x로 같아지게 됩니다. F(x) = H(x) - x이므로 F(x)를 최소로 해준다는 것은 H(x) - x를 최소로 해주는 것과 동일한 의미를 지닙니다. 여기서 H(x) - x를 잔차(residual)라고 합니다.
즉, 잔차를 최소로 해주는 것이므로 ResNet이란 이름이 붙게 됩니다.
Residual Learning : 지름길(Shortcut)
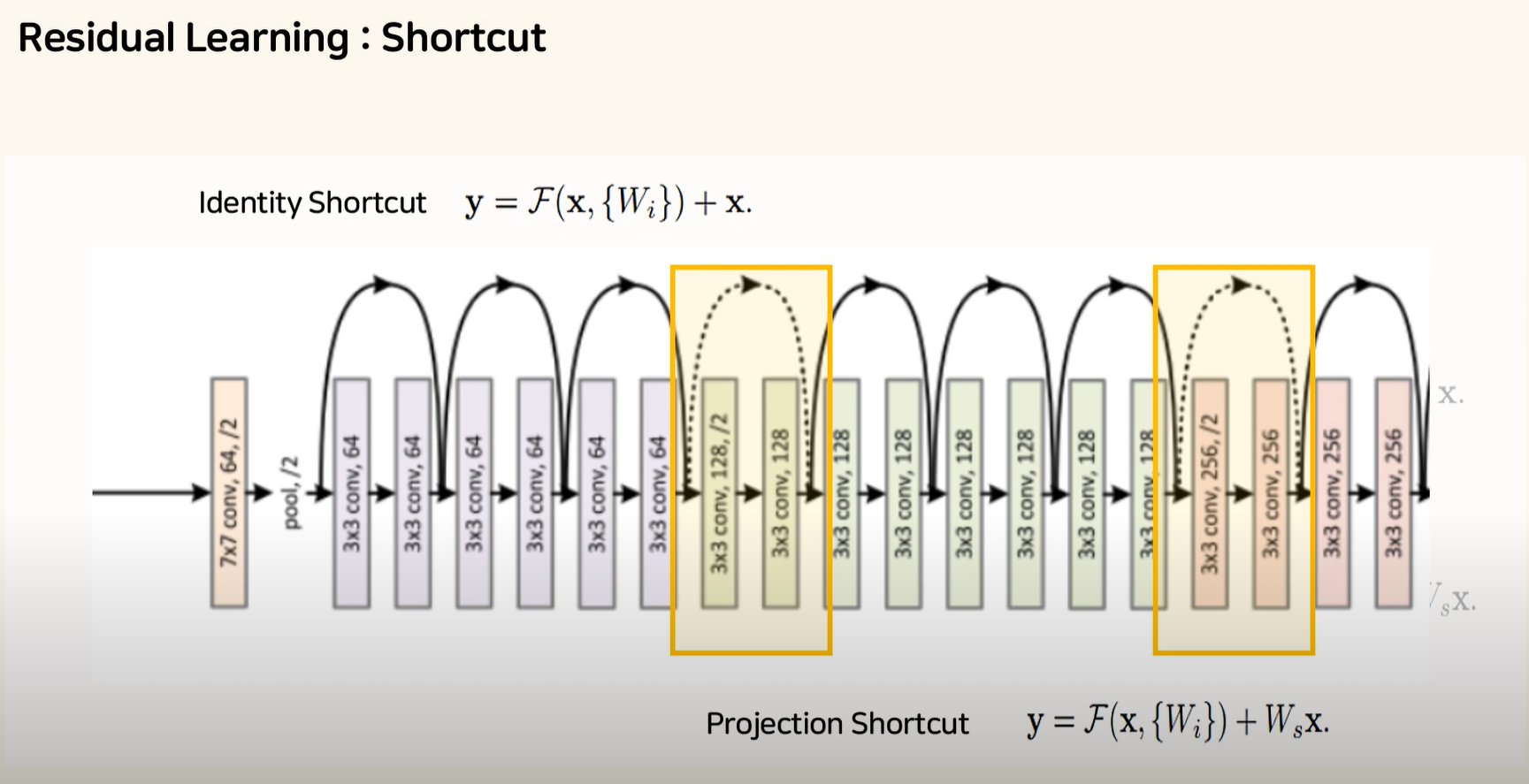
지름길(Shortcut)을 자세히 한번 더 살펴보겠습니다.
두 개의 Convolution Layer 마다 옆으로 화살표가 빠져나간 뒤 합쳐지는 식으로 그려지게 됩니다.
이런 구조를 지름길(Shortcut) 구조라고 말합니다.
일반적으로 지름길(Shortcut)은 Identity Shortcut 즉, Input Feature Map x를 그대로 Output에 더해주는 연산을 해주게 됩니다.
다음은 34 ResNet의 일부를 가지고 온 것입니다.
그림을 자세히 보시면 Convolution 연산과 Feature Map 개수가 바뀌면서 네모 박스의 색이 바뀌는 것을 볼 수 있습니다. 색이 바뀔 때마다 실선이 아닌 점선들이 한번 나오는 것을 확인하실 수 있습니다.
기본적으로 실선은 아까 소개했던 그냥 더해주는 Identity 지름길(Shortcut) 과정을 말해줍니다.
하지만 여기서 네모 박스 색이 바뀌는 부분에서는 Out Feature Map의 개수가 두배로 커질 때마다 Feature Map의 가로세로 사이즈가 절반으로 줄여주는 방식을 이용하고 있으며,
이 경우 사이즈가 줄어드니까 지름길(Shortcut)에서도 Feature Map의 사이즈를 줄여주어야 하며,
이때는 Identity 지름길(Shortcut) 대신 Projection 지름길(Shortcut)을 사용하게 됩니다.
ResNet의 구조
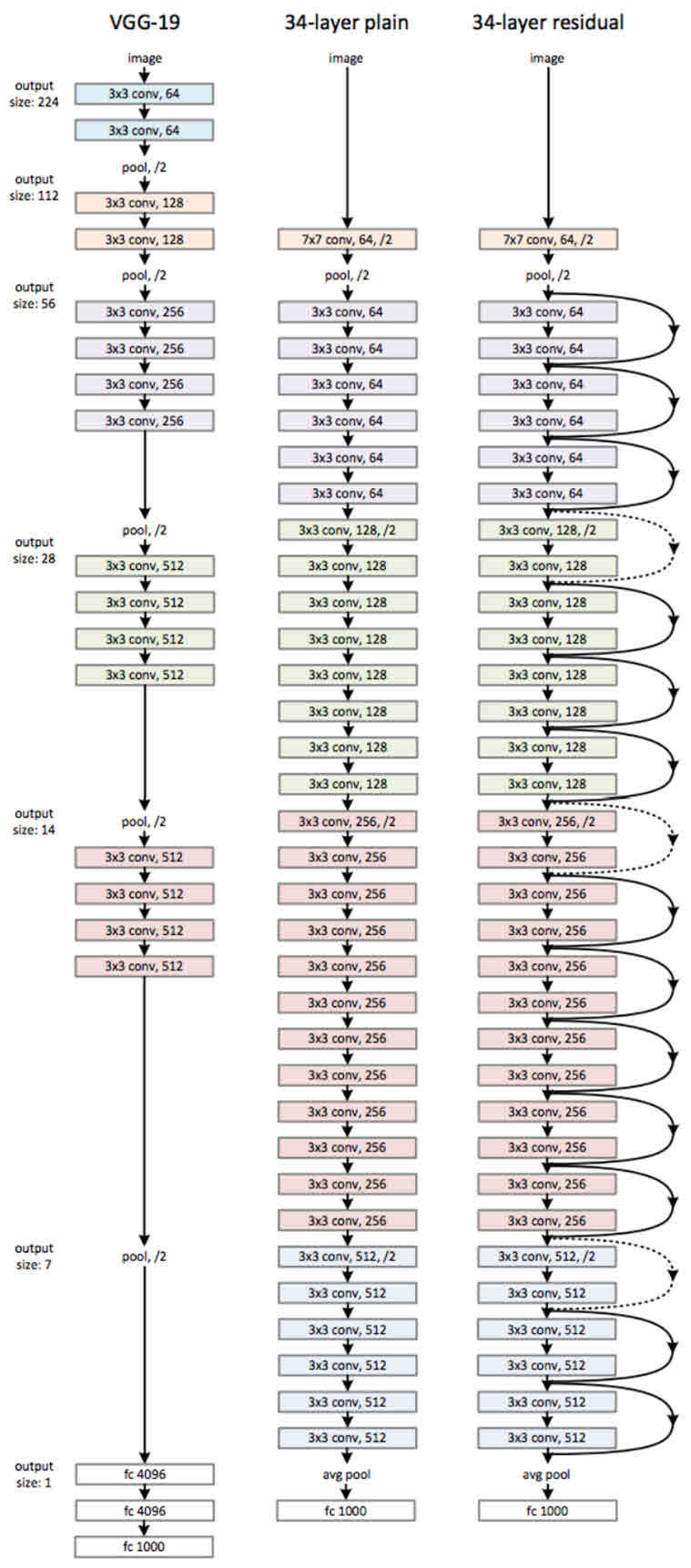
ResNet은 기본적으로 VGG-19의 구조를 뼈대로 합니다.
거기에 Convolution 층들을 추가해서 깊게 만든 후에, shortcut들을 추가하는 것이 사실상 전부입니다.
34층의 ResNet과 거기에서 shortcut들을 제외한 버전인 plain 네트워크의 구조는 해당 그림과 같습니다.
그림을 보면 알 수 있듯이 34층의 ResNet은 처음을 제외하고는 균일하게 3x3사이즈의 Convolution필터를 사용했습니다. 그리고 Feature Map의 사이즈가 반으로 줄어들 때, Feature Map의 Depth를 2배로 높였습니다.
저자들은 과연 shortcut, 즉 Residual block들이 효과가 있는지를 알기 위해 이미지 넷에서 18층 및 34층의 plain 네트워크와 ResNet의 성능을 비교했습니다.
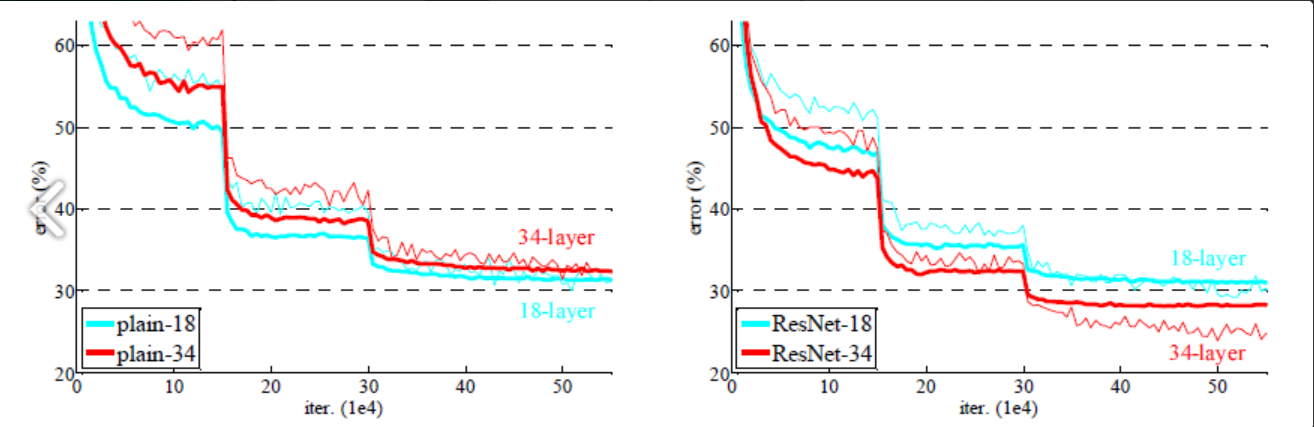
왼쪽 그래프를 보면 plain 네트워크는 망이 깊어지면서 오히려 에러가 커졌음을 알 수 있습니다.
34층의 plain 네트워크가 18층의 plain 네트워크보다 성능이 나쁩니다.
반면, 오른쪽 그래프의 ResNet은 망이 깊어지면서 에러도 역시 작아졌습니다.
shortcut을 연결해서 잔차(residual)를 최소가 되게 학습한 효과가 있다는 것입니다.
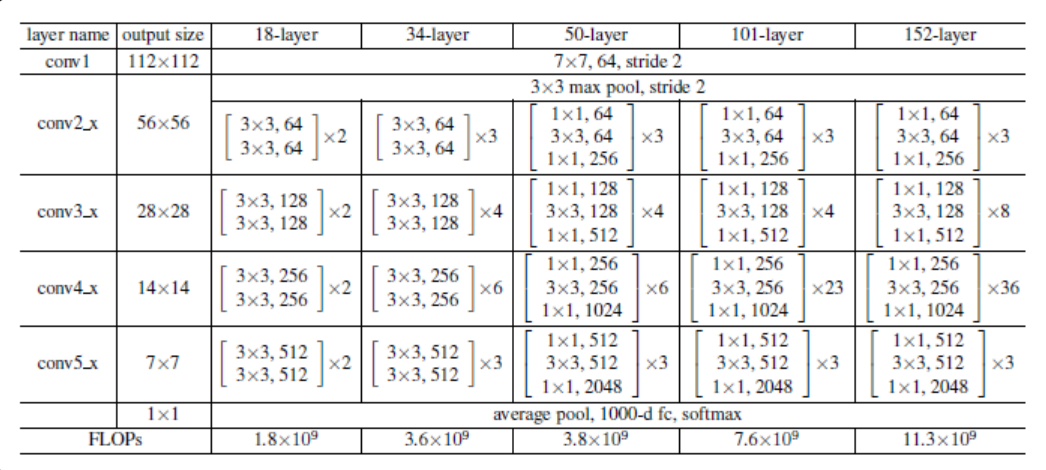
아래 표는 18층, 34층, 50층, 101층, 152층의 ResNet이 어떻게 구성되어 있는가를 잘 나타내 줍니다.
깊은 구조일수록 성능도 좋습니다. 즉, 152층의 ResNet이 가장 성능이 뛰어납니다.
'Main > Paper Review' 카테고리의 다른 글
| [Paper Review] MobileNet V1 (0) | 2022.05.26 |
|---|---|
| [Paper Review] SENet: Squeeze-and-Excitation Networks (0) | 2022.05.16 |
| [Paper Review] Batch Normalization (1) | 2022.03.31 |
| [CNN-Algorithm] GoogLeNet(Inception) (0) | 2022.03.21 |
| [CNN-Algorithm] VGGNet (0) | 2022.03.21 |




댓글