"Transformer: Attention Is All You Need"
논문 리뷰입니다.
https://arxiv.org/pdf/1706.03762.pdf
오늘은 현재까지 자연어 처리 분야뿐만 아니라 최근에는 이미지 분야 딥러닝 모델에 중대한 영향을 끼치고 있는 논문인 Transformer( NIPS 2017 )를 소개해보도록 하겠습니다.
목차
Transformer 소개

전반적인 Transformer model의 구조입니다.
Transformer는 기존 encoder, decoder를 발전시킨 딥러닝 모델입니다.
가장 큰 차이는 RNN을 사용하지 않는다는 점입니다.
Transformer를 한 단어로 설명한다면 병렬화라고 할 수 있습니다.
쉽게 말해서 Transformer는 이를 최대한 한 번에 처리합니다.
Transformer에는 크게 4가지 정도의 개념들이 있습니다.
1. Positional encoding
2. Self Attention
3. Multi Head Attention
4. Encoder & Decoder 구조
에 대한 내용이 있습니다.
우선 Transformer논문을 본격적으로 살펴보기 전에
배경적인 요소들부터 살펴보겠습니다.
Background(배경지식)
Attention을 활용하는 encoder & decoder의 가장 큰 진보된 점은 고정된 크기의 context vector를 사용하지 않는다는 점이 있습니다. 대신 단어를 하나씩 번역할 대마다 동적으로 encoder 출력 값에 Attention 메커니즘을 수행해서 효율적으로 번역을 한다는 큰 장점이 있습니다.
동적으로 encoder를 활용하기 때문에 긴 문장의 번역 성능이 이전 encoder & decoder 성능보다 나아졌습니다.
attention 메커니즘은 기존 encoder & decoder 성능을 강화시켰음으로 큰 주목을 받았습니다.
하지만 여전히 RNN cell을 순차적으로 계산해서 느리다는 단점이 존재했고 성능도 더 높일 수 있는 가능성이 충분히 있었습니다.
사람들은 RNN을 대신해서 성능좋은 모델을 찾기 위해 고민을 했고 Attention만으로도 입력 데이터에서 중요한 정보를 찾아내서 단어를 encoding 할 수 있지 않을까 생각을 했습니다.
이것이 Attention Is All You Need의 탄생입니다.
Transformer는 한번의 연산으로 모든 중요정보들을 각 단어에 encoding을 하게 됩니다.
Transformer에서 가장 큰 특징은 RNN을 성공적으로 encoder & decoder에서 제거했다는 것입니다.
decoder의 번역과정은 기존 encoder & decoder방법과 동일하게 start 사인에서 end사인까지 번역을 하게 됩니다.
이 대목에서 Transformer는 기존 encoder & decoder의 컨셉을 간직하고 있다는 것을 확인할 수 있습니다.
기존 encoder & decoder의 컨셉을 간직하되 RNN을 없애서 학습 시간을 단축했고
Attention 뿐만 아니라 더 많은 스마트한 기술을 제공해서 성능을 올렸습니다.
자연어 처리에서 문장을 처리할 때 실제 단어의 위치 및 순서는 상당히 중요합니다.
RNN이 자연어처리에 상당히 많이 활용되는 이유도 바로 이 RNN이 단어의 위치와 순서 정보를 잘 활용하는 데 있기 때문입니다.
그렇다면 RNN이 없는 Transformer는 어떻게 단어의 위치 및 순서 정보를 활용할 수 있을까요?
정답은 바로 Positional Encoding 기술 입니다.
RNN을 사용하지 않으려면 위치 정보를 포함하고 있는 임베딩을 사용해야 합니다.
encoder 및 decoder 입력 값마다 상대적인 위치정보를 더해주는 기술입니다.
Positional Encoding

해당 사진에서는 vector를 작은 연속된 상자로 나타내 보았습니다.
간단한 비트를 사용한 Positional encoding 예제입니다.
슬라이드 첫 번째 단어 i에는 001을 더해주고, study에는 010, at에는 011, school에는 100을 더해줬습니다.
똑같은 방식으로 decoder에 입력값에도 Positional encoding을 적용해줄 수 있습니다.
Transformer에서는 이러한 예처럼 비트의 Positional encoding이 아닌 sin과 cos함수를 활용한 Positional encoding을 활용합니다.

sin cos을 활용한 positional encoding은 두 가지 장점이 있습니다.
- 항상 positional encoding 값을 -1~1 사이의 값이 나온다.
- 모든 상대적인 positional encoding 장점으로써 학습 데이터중 가장 긴 문장보다도 더 긴 문장이 실제 운영중에 들어와도 positional encoding이 에러없이 상대적인 인코딩값을 줄수있다는 점이다.
각 단어 워드 임베딩에 Positional encoding을 더해준 후에 해줘야 할 것은 바로 Self-Attention 연산입니다.
Self Attention
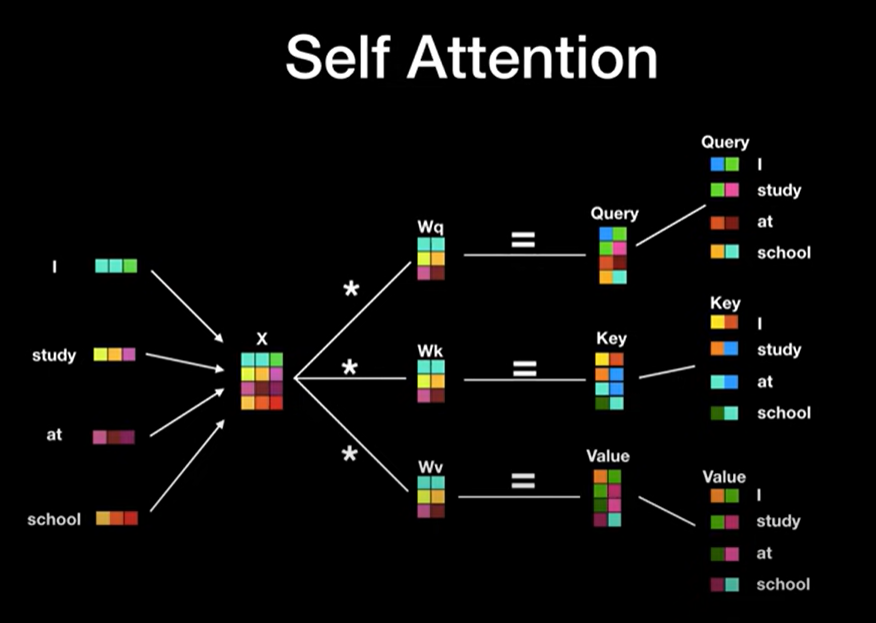
Self-Attention 연산이란 '각각의 단어가 서로에게 어떤 연관성을 가지고 있는지'를 파악하는 기술입니다.
예를 들어 i am a student라는 문장이 있을 때
i, am, a, student라는 단어가 서로에게 어떤 연관성이 있는지를 계산을 한 후에 더 중요한 벡터 성분을 추출합니다.
즉, 미리 전체 문장을 한번 파악하고 그 문장에서 이 단어가 어떤 관계를 하고 있는지도 파악하여 후에 encoder 작업을 실시하는 것입니다.
해당 과정에서는 처음 접해볼 수 있는 변수들이 등장합니다.
query: 물어보는 주체, 현재 단어, Attention 계산에서 기준이 되는 vector
key: 물어보는 대상, vector와 호환성이 높은 단어를 찾기 위한 vector
value: 최종 representation을 얻기 위한 vector, 다른 단어와의 Attention이 반영
다시 말해 좀 더 중요하고, 농축된 vector로 만들기 위해 위 변수들을 이용하여 계산 작업을 진행합니다.
wq, wk, wv 행렬은 weight matrix로 딥러닝 모델 학습 과정을 통해 최적화되고 이를 통해
각각 query, key, value가 생성이 됩니다.


각각의 단어가 서로에게 어떤 연관성을 가지고 있는지 연산하는 과정입니다.
현재 단어를 query라고 설정합니다.
연관성을 보고 싶은 단어를 key라고 합니다.
이 query를 와 key를 곱한 값을 Attention score, 즉 위 그림의 Score에 해당되는 값입니다.
query와 key가 둘 다 vector이므로 곱할 경우 그 결과는 숫자로 나오게 됩니다.
Attention을 0부터 1까지의 확률 개념으로 바꾸기 위해 softmax를 적용해줍니다.
숫자가 높을수록 단어의 연관성이 높고 낮을수록 연관성이 낮다라고 생각할 수 있습니다.
논문에서는 softmax를 적용하기 전에 score를 key vector 차원수의 루트 값으로 나눠줬는데
논문에 따르면 key vector의 차원이 늘어날수록 dot product 계산 값이 증대되는 문제를 보완하기 위해 이런 조치를 취했다고 합니다.

softmax의 결괏값을 key 값에 해당하는 단어가 현재 단어에 어느 정도 연관성이 있는지를 나타냅니다.
예를 들어서 단어 i는 자기 자신과 92% study 5% at 2% school 1%의 연관성이 있다고 생각을 할 수가 있습니다.
각 %를 각 key에 해당하는 value에 곱해줍니다. 연관성이 별로 없는 value값은 거의 희미해졌습니다.
최종적으로 어텐션이 적용이 되어 희미해진 이 value들을 모두 더해준다.
즉, 이 최종 벡터는 이제 단순히 단어 i가 아닌 문장 속의 서의 단어 i가 지닌 전체적인 의미를 지닌 벡터라고 간주할 수 있게 됩니다.
위 그림처럼 입력 문장 전체는 행렬로 표시할 수가 있습니다.
query, key, value 모두 행렬로 저장이 되어있으니까 모든 단어에 대한 모든 attention 연산은 행렬곱을 통해 한번에 처리를 할 수 있습니다.
RNN을 사용했다면 처음 단어부터 끝 단어까지 순차적으로 계산을 했었어야 했을 겁니다.
이것이 바로 Attention을 사용한 병렬 처리의 가장 큰 장점입니다.

Multi Head Attention
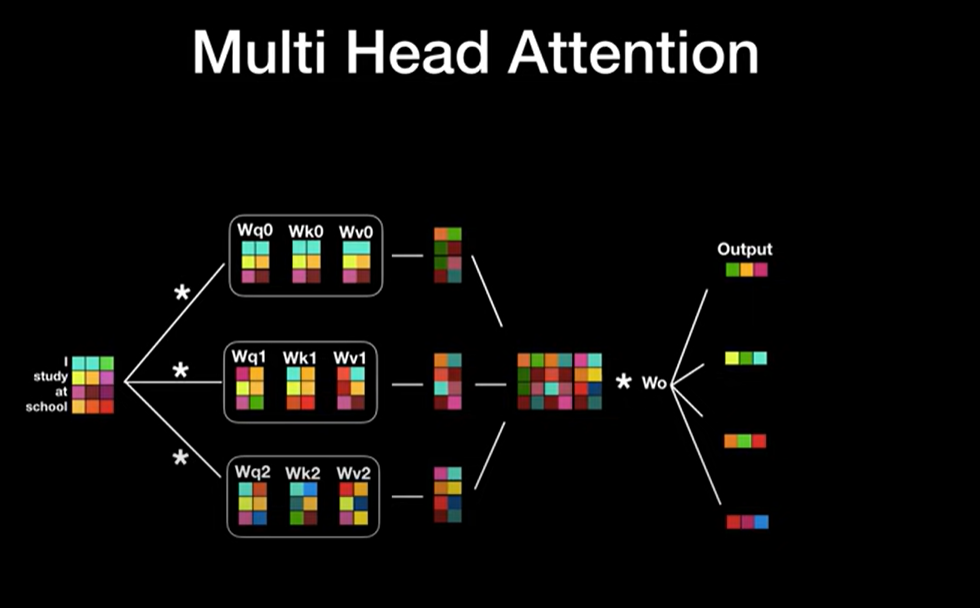
CNN에서 여러 개의 feature map을 사용하는 것처럼 Transformer에서도 여러 개의 Self-Attention 연산을 사용할 수 있습니다.
현재 슬라이드에서는 간단하게 3개의 Attention layer를 수행하지만, 실제로 논문에서는 8개를 사용했습니다.
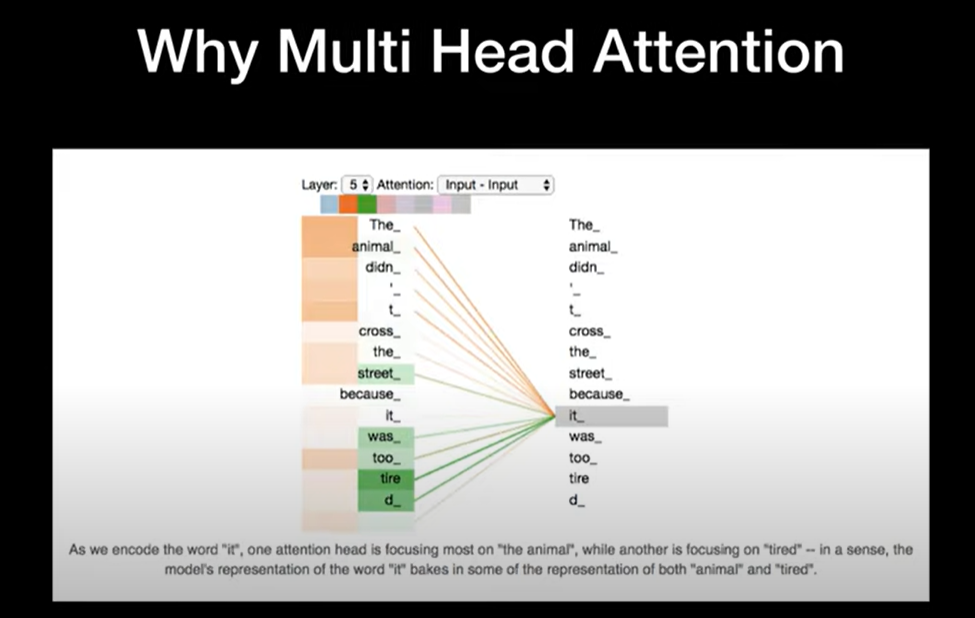
여러개의 Attention layer를 병렬 처리함으로써 얻는 이점이 무엇일까요?
병렬 처리된 Attention layer를 Multi Head Attention이라고 부릅니다.
그리고 Multi Head Attention은 예제와 같은 기계번역에 큰 도움을 줍니다.
사람의 문장은 모호할 때가 상당히 많고 한 개의 Attention을 하면 모호한 점을 충분히 encoding 하기 어렵기 때문에 Multi Head Attention을 사용해서 되도록 연관된 정보들을 다른 관점에서 수집하여 이 점을 보완할 수 있습니다.
이것이 바로 Multi Head Attention입니다.
Encoder 구조
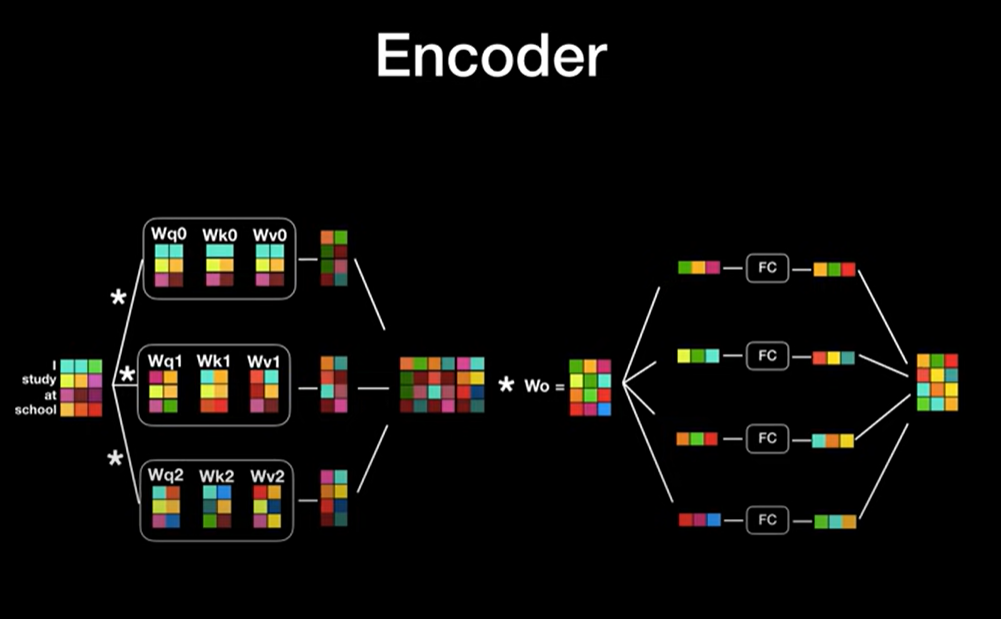
Encoder의 구조 사진입니다.
단어를 워드 임베딩 하여 벡터로 전환 후 Positional encoding을 적용합니다.
그리고 Multi Head Attention에 입력을 합니다.
Multi Head Attention을 통해 출력된 여러 개의 결괏값들을 모두 이어 붙여서
또 다른 행렬과 곱하여 결국 최초 워드 임베딩과 동일한 차원을 갖는 벡터로 출력이 됩니다.
각각의 벡터는 따로따로 Fully connected layer로 들어가서 입력과 동일한 사이즈의 벡터로부터 다시 출력이 됩니다.
무엇보다 출력 벡터의 차원의 크기가 입력 벡터와 동일하다는 것이 중요합니다.
딥러닝 모델을 학습하다 보면 역전파로 인해 Positional encoding이 많이 손실될 수가 있습니다.
이를 보완하기 위해 Residual Learning(잔여 학습: resnet에서 사용했던)으로 입력된 값을 다시 한번 더해주는 것도 눈여겨봐야 될 점입니다.
Residual Learning뒤에는 normalization을 사용해서 학습의 효율을 또 증진시킵니다.
여기까지가 바로 encoder layer입니다.
아까 encoder layer의 입력 벡터와 출력 벡터의 차원의 크기가 같다는 것 기억하시죠?
이 말은 즉슨 encoder layer를 여러 개 붙여서 사용할 수 있다는 뜻입니다.

Transformer의 encoder는 실제 이 encoder layer를 6개 연속적으로 붙인 구조입니다.
중요한 점은 각각의 encoder layer는 서로의 모델 파라미터 즉 가중치를 공유하지 않고 따로 학습시킵니다.
Decoder 구조

지금 보시는 건 decoder layer입니다.
decoder도 encoder와 상당히 유사한 구조를 지니고 있지만 몇 가지 차이점들이 있습니다.
하나의 decoder layer에서는 두 개의 Attention을 사용합니다.
첫 번째로 보이는 Attention은 Self-Attention입니다.
encoder 파트와 마찬가지로 각각의 단어들이 서로가 서로에게 어떠한 가중치를 가지는지를 구하도록 만들어서 출력되고 있는 문장에 대한 전반적인 표현을 학습할 수 있도록 만듭니다.
또한 Masked Multi Head Attention이라고도 불립니다.
지금까지 출력된 값들에게만 Attention을 적용하기 위해서 붙여진 이름입니다.
decoder시에 아직 출력되지 않은 미래의 단어에 Attention을 적용하면 안 되기 때문이죠
두 번째로 보이는 Attention은 encoder에 대한 정보를 Attention 할 수 있도록 만듭니다.
각각의 출력 단어가 encoder에 출력 정보를 받아와 사용할 수 있도록 만듭니다.
다시 말해 각각의 출력되고 있는 단어가 소스 문장에서의 어떤 단어와 연관성이 있는지를 구해주는 것입니다.
그래서 두 번째 Attention과정은 일반적으로 encoder - decoder Attention이라고 불립니다.
decoder의 출력 단어가 query가 되는 것이고, 각각의 출력 단어를 만들기 위해서 encoder 파트에서의 어떤 단어를 참고하면 좋을지를 구하기 위해서 이 key랑 value는 encoder의 출력 값으로 쓰겠다는 뜻입니다.
다시 말해 각각의 단어를 출력하기 위해 "어떤 정보를 참고해야 해?"라고 encoder에게 물어보는 것이기 때문에 decoder에 있는 단어가 query가 되고 encoder에 있는 각각의 값들이 key와 value가 됩니다.
예를 들어
만약 입력 문장이 i am a teacher라고 한다면, 출력 값을 차례대로 나는 선생님이다라고 출력을 내뱉을 것입니다.
이때 출력되고 있는 단어들, 예를 들어 선생님이라고 단어를 번역한다고 하면
그 선생님이라는 단어는 i am a teacher 중에서 어떤 단어와 가장 높은 연관성을 가지는지를 구할 수가 있는 것입니다.
그런 정보를 매번 Attention을 통하여 계산하도록 만들어서 이렇게 encoder 파트에서 나왔던 출력 결과를 전적으로 활용하도록 네트워크를 설계할 수 있는 것입니다.
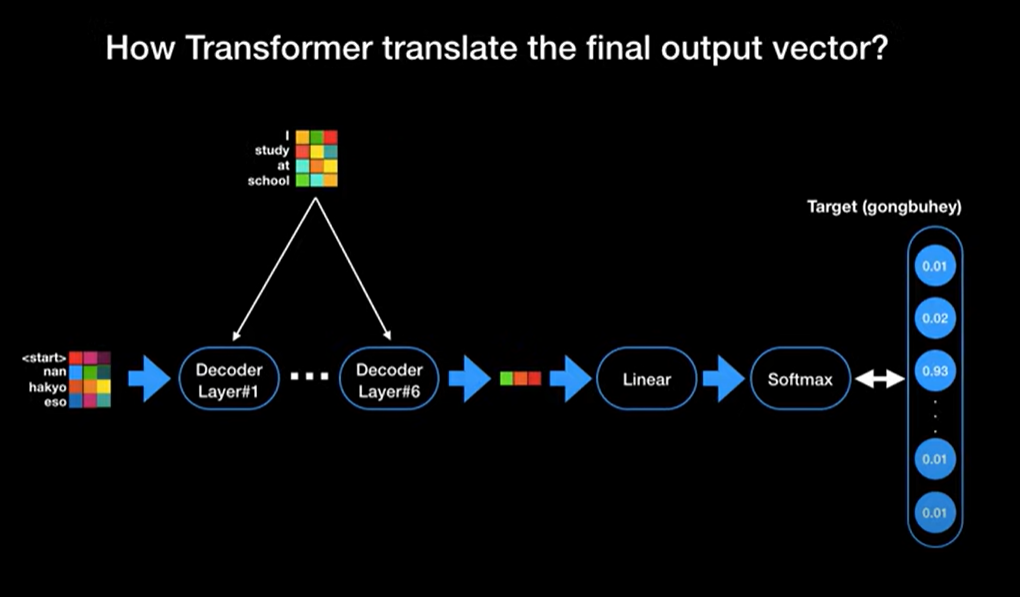
decoder layer도 encoder와 같이 6개의 동일한 layer 개수로 구성이 되어 있습니다.
그렇다면 이 벡터들을 실제 단어로 어떻게 출력할 수 있을까요?
실제 단어로 출력하기 위해서 decoder 최종 단계에는 linear layer와 softmax layer가 존재합니다.
linear layer는 softmax의 입력 값으로 들어갈 logit을 생성하는 것이고
softmax를 통해 모든 단어들에 대한 확률 값을 출력함으로써 가장 높은 확률을 지닌 값이 바로 다음 단어가 되는 것입니다.
Transformer의 최종단계에도 label smoothing이라는 기술을 사용해서 model 퍼포먼스를 다시 한번 한 단계 업그레이드시킵니다.
label smoothing 설명
보통 딥러닝 모델을 소프트맥스로 학습할 경우 레이블을 원핫인코딩으로 전환을 해주는데
이번 슬라이드에서 확인할 수 있듯이 트랜스포머는 원핫인코딩이 아닌 뭔가 1에는 가깝지만 1이 아니고 0에는 가깝지만 0이 아닌 값으로 표현되어 있는 것을 눈으로 확인할 수 있습니다.
이 기술을 label smoothing이라고 합니다.
0 또는 1이 아닌 정답은 1에 가까운 값 오답은 0에 가까운 값으로 이렇게 살짝살짝 변화를 주는 기술입니다.
모델을 학습 시에 모델이 너무 학습 데이터에 치중하여 학습하지 못하도록 보완하는 기술입니다.
자 이것이 어떻게 학습이 도움이 될지 궁금할 수 있을 거예요.
학습 데이터가 매우 깔끔하고 예측할 값이 확실할 경우에는 도움이 안 될 수 있습니다.
하지만 label이 noisy 한 경우 즉 같은 입력값인데 다른 출력 값들이 학습 데이터들에 많을 경우
label smoothing은 큰 도움이 됩니다. 왜냐하면 학습이라는 것은 소프트맥스의 출력 값과 벡터로 전환된 label의 차이를 줄이는 것인데 같은 데이터에 서로 상이한 정답들이 원핫인코딩으로 존재한다면
모델 파라미터가 크게 커졌다가 작아졌다가 반복하고 학습이 원활하지 않습니다.
실제 예제를 들어보자면 영어로 'thank you'에 대한 학습 데이터가 있을 때
첫 번째 레이어는 '고마워', 두 번째는 '감사합니다'라고 되어있을 수 있습니다
두 학습 데이터는 모두 잘못된 게 아닙니다.
하지만 원핫인코딩을 이 두 레이블에 적용 시 '고마워'와 '감사합니다'는 완전히 다른 상이한 두 벡터가 되고 thank you에 대한 학습은 레이블이 상이한 이유로 원활하게 진행이 안될 수도 있습니다.
이럴 경우 label smoothing을 적용을 하면 '고마워'와 '감사합니다'는 원핫인코딩 보다는 조금은 가까워진 벡터가 되고 또한 소프트맥스 출력 값과 레이블의 차이 역시 조금은 줄어들어서 효율적인 학습을 기대할 수 있게 되는 것입니다.
참고자료
'Main > Paper Review' 카테고리의 다른 글
| [Paper Review] FixMatch: Simplifying Semi-Supervised Learningwith Consistency and Confidence (0) | 2023.03.17 |
|---|---|
| [Paper Review] LWF: Learning Without Forgetting (0) | 2022.12.19 |
| [Paper Review] MobileNet V1 (0) | 2022.05.26 |
| [Paper Review] SENet: Squeeze-and-Excitation Networks (0) | 2022.05.16 |
| [Paper Review] Batch Normalization (1) | 2022.03.31 |




댓글