FixMatch: Simplifying Semi-Supervised Learningwith Consistency and Confidence
https://arxiv.org/abs/2001.07685
목차
FixMatch는 최근 연구에서 나온 semi-supervised learning 방법 중 하나로, 라벨이 없는 대량의 데이터를 이용하여 모델의 성능을 향상시키는 방법이다.
이전에는 labeled 데이터가 많지 않은 경우에는 모델의 성능을 높이기가 어려웠는데, FixMatch는 이러한 한계를 극복하고자 한다.
해당 리뷰 글은 논문 원본에 근거하여 개인 정리 용도로 작성하였으니 참고바랍니다.
Abstract
본 논문에서는 기존 Semi-Supervised Learning 방법을 크게 단순화한 algorithm인 FixMatch를 제안한다.
FixMatch는 먼저 weakly-augmented unlabeled image에 대한 모델의 예측을 사용하여 유사 레이블을 생성한다.
주어진 이미지의 경우 모델이 높은 신뢰도 예측을 생성하는 경우에만 pseudo-label이 유지된다.
그런 다음 모델은 strongly-augmented version of the same image을 제공할 때 pseudo-label을 예측하도록 훈련된다.
이렇게 간단함에도 불구하고, FixMatch는 기존 semi-supervised learning과 비교하여 SOTA를 달성했다.
1. Instroduction
Deep Neural Network의 성공은 더 큰 data set에서 훈련하면 더 나은 성능을 얻을 수 있다는 확장성 관련한 empirical observation에 기인한다.
하지만, labeled data에는 human labor가 필요하기 때문에, 더 큰 data set 사용으로 인한 성능 이점은 significant 한 cost가 들 수 있다.
semi-supervised learning은 unlabeld data를 활용하는 방법을 제공하여 labeled data에 대한 요구 사항을 완화한다.
SSL의 인기 있는 방법은 unlabeled image에 대한 인공 label을 생성하고 unlabeled image를 입력으로 공급할 때 모델이 인공 레이블을 예측하도록 훈련하는 것으로 볼 수 있다.
FixMatch는 Consistency regularization과 pseudo-labeling을 모두 사용하여 인공 label을 생성한다.
결정적으로, 인공 레이블은 모델이 strongly-augmented version of the same image를 제공할 때 대상으로 사용되는 weakly-augmented unlabeled image를 기반으로 생성된다.
pseudo-labeling의 접근 방식에 따라 모델이 가능한 클래스 중 하나에 높은 확률을 할당하는 경우에만 인공 레이블을 유지한다.

모형이 threshold(임계치) 보다 높은 클래스에 확률을 할당하면 예측은 one-hot pseudo-label로 변환된다.그런 다음 strong augmentation of the same image에 대한 모델의 예측을 계산한다.
이 모델은 strongly-augmented version에 대한 예측이 cross-entropy loss을 통해 pseudo-label과 일치하도록 훈련된다.기존 방법을 단순화하는 FixMatch의 주요 이점은 추가 hyper paramter가 훨씬 적다는 것이다.
FixMatch는 기존 접근 방식을 단순화하지만 훨씬 더 나은 성능을 달성하기 때문에,
어떤 요인이 성공에 가장 크게 기여하는지를 결정하기 위한 extensive ablation study를 포함한다.
ablation study내용을 통해 구체적인 성공요인을 알 수 있어서 직접 정독해 보는 것을 추천한다.
2. FixMatch
FixMatch는 SSL에 대한 두 가지 접근 방식, 즉 Cosistency regularization and pseudo-labeling의 조합이다.
L개의 클래스 분류 문제의 경우,
X = {(xb , pb) : b ∈ (1,…, B) }는 B는 labeled examples이고, xb 는 training examples이며 pb는 one-hot labels입니다.
X = { pb : b ∈ (1,…,μB) }는 μ*B는 unlabeled examples이고, μ는 x와 u의 상대적 크기를 결정하는 hyperparameter입니다.
pm(y|x) 를 입력 x에 대한 모형에 의해 생성된 예측 클래스 분포라고 하자.
우리는 두 확률 분포 p와 q 사이의 cross-entropy를 H(p, q)로 나타낸다.
우리는 FixMatch의 일부로 A(⋅)와 α(⋅)로 각각 표시되는 두 가지 유형의 증강을 수행한다.
2.1 Background
Consistency regularization is an important component of recent state-of-the-art SSL algorithms.
Consistency regularization는 동일한 이미지의 교란된 버전을 공급할 때
모델이 유사한 예측을 출력해야 한다는 가정에 의존하여 unlabeled data를 활용한다.
(1)
α 랑 pm 는 확률함수이다.
so, the two terms in eq (1) will indeed have different values.

이 아이디어의 확장에는
1. α 대신 adversarial transformation 사용
2. pm 의 한 번의 호출에 대한 실행 평균 또는 과거 모델 예측 사용
3. 제곱 L2-loss 대신 Cross-entropy loss 사용
4. stronger forms of augmentation 사용
5. 더 큰 SSL 파이프라인의 구성 요소로 consistency regularization 사용이 포함된다.
(2)
Pseudo-labeling leverages the idea of using the model itself to obtain artificial labels for unlabeled data.
최대 클래스 확률이 사전 정의된 임계값보다 높은 인공 레이블만 유지합니다.

qb = pm(y | ub), pseudo-labeling uses the following loss function
qˆb = argmax(qb) and γ is the 임계값.
For simplicity, we assume that argmax applied to a probability distribution produces a valid “one-hot” probability distribution.
여기서 모델의 예측은 unlabeled data에 대한 낮은 엔트로피(즉, 높은 신뢰도)로 권장된다.
2.2 Our Algorithm: FixMatch
The loss function for FixMatch consists of two cross-entropy loss terms.
A supervised loss Ls applied to labeled data and an unsupervised loss Lu
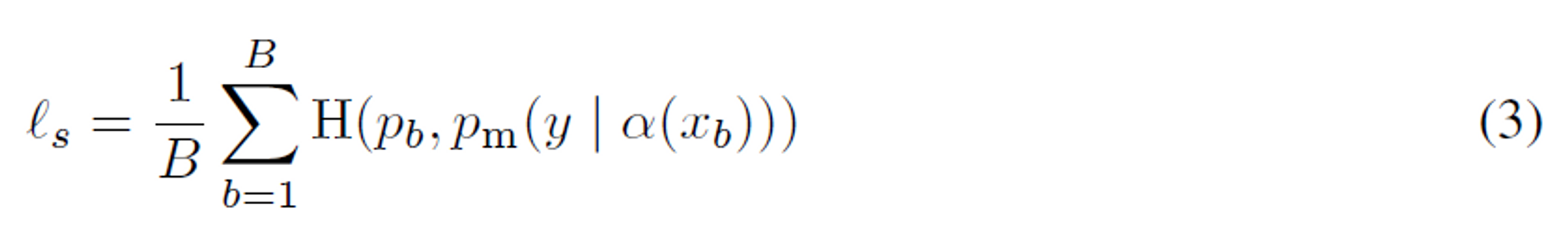
Ls 는 weakly augmented labeled examples에서 standard cross-entropy loss
α는 weakly-augmentation
pm은 예측 클래스 분포.
xb는 training examples
즉, pm(y | α(xb)) weakly-augmented에 의해서 생성된 training 샘플들에 대한 모형에 의해 생성된 예측 클래스 분포, pb는 one-hot labels입니다.
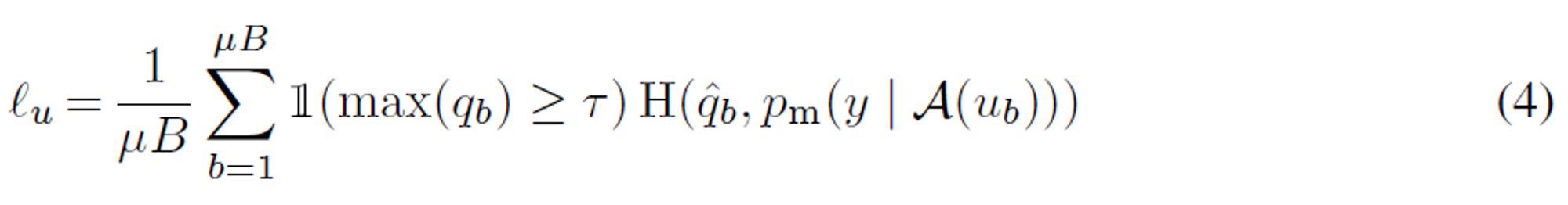
FixMatch는 레이블이 지정되지 않은 데이터에 대한 인공 레이블을 계산한 다음 standard cross-entropy loss에 사용됩니다.
인공 레이블을 얻기 위해, 우리는 먼저 주어진 레이블이 없는 이미지의 weakly-augmented 버전이
주어진 모델의 예측된 클래스 분포를 계산한다: qb = pm(y | α(ub)).
except we enforce the cross-entropy loss against the model’s output for a strongly-augmented version of u_b, Then, we use qˆb = argmax(qb) as a pseudo-label
γ is a scalar hyperparameter denoting the threshold above which we retain a pseudo-label.
FixMatch에 의해 최소화된 손실은 간단히 Ls+ λuLu이며, 여기서 λu는 레이블이 지정되지 않은 손실의 상대적 가중치를 나타내는 고정 스칼라 하이퍼 파라미터이다.
우리는 또한 typical in modern SSL algorithms에서 the weight of the unlabeled loss term (λu) during training의 가중치를 증가시키는 것이 일반적이라는 점에 주목한다.
우리는 이것이 FixMatch에 불필요하다는 것을 발견했는데, 이는 훈련초기에 max(qb)가 일반적으로 γ 작기 때문일 수 있다.
2.3 Augmentation in FixMatch
weak augmentation is a standard flip-and-shift augmentation strategy.
For “strong” augmentation, we experiment with two methods based on AutoAugment
AutoAugment는 강화 학습을 사용하여 Python Imaging Library의 변환으로 구성된 augmentation strategy을 찾는다.
이를 위해서는 augmentation strategy을 학습하기 위해 레이블이 지정된 데이터가 필요하므로 제한된 레이블이 지정된 데이터를 사용할 수 있는 SSL 설정에서 사용하는 것이 문제가 된다.
결과적으로, RandAugment 및 CTAugment와 같이 레이블이 지정된 데이터로 사전에 증강 전략을 학습할 필요가 없는 변형된 AutoAugment가 제안되었다.
학습된 전략을 사용하는 대신 RandAugment와 CTAugment 모두 각 표본에 대한 변환을 랜덤 하게 선택합니다.
2.4 Additional important factors
Semi-supervised performance는 the amount of regularization과 같은 고려 사항이 낮은 레이블 체제에서
특히 중요할 수 있기 때문에 사용된 SSL 알고리즘 이외의 요소에 의해 크게 영향을 받을 수 있다.
이는 이미지 분류를 위해 훈련된 심층 네트워크의 성능이 architecture, optimizer, training schedule 등에 크게 좌우될 수 있다는 사실에 의해 더욱 복잡해진다.
우리의 모든 모델과 실험에서, 우리는 간단한 weight decay regularization를 사용한다.
또한 Adam optimizer를 사용하면 성능이 저하되고 대신 standard SGD with momentum를 사용한다는 것을 발견했다.
우리는 standard and Nesterov momentum 사이에 상당한 차이를 발견하지 못했다.
we use a cosine learning rate decay
마지막으로 모델 매개 변수의 exponential moving average을 사용하여 최종 성능을 보고한다.
4. Experiments
We evaluate the efficacy of FixMatch on several SSL image classification benchmarks.
In many cases, FixMatch가 극단적으로 레이블이 부족한 설정에서 가능성을 보여주기 때문에 이전에 고려된 것보다 더 적은 레이블로 실험을 수행한다.
4.1 CIFAR-10, CIFAR-100, and SVHN
We compare FixMatch to various existing methods on the standard CIFAR-10, CIFAR-100, and SVHN benchmarks.
Besides, 이전 연구에서는 이러한 벤치마크에서 클래스당 25개 미만의 레이블을 고려하지 않았다.
우리는 또한 각 데이터 세트에서 각 클래스에 대해 4개의 레이블이 지정된 이미지만 제공되는 설정을 고려한다.
우리가 아는 한 CIFAR-100에서 클래스당 4개의 레이블에서 실험을 실행한 것은 우리가 처음이다.
CIFAR-10: 10개의 클래스 > 클래스당 4, 25, 400개
CIFAR-100: 100개의 클래스 > 4, 25, 100
SVHN: 10개의 클래스 > 4, 25, 100
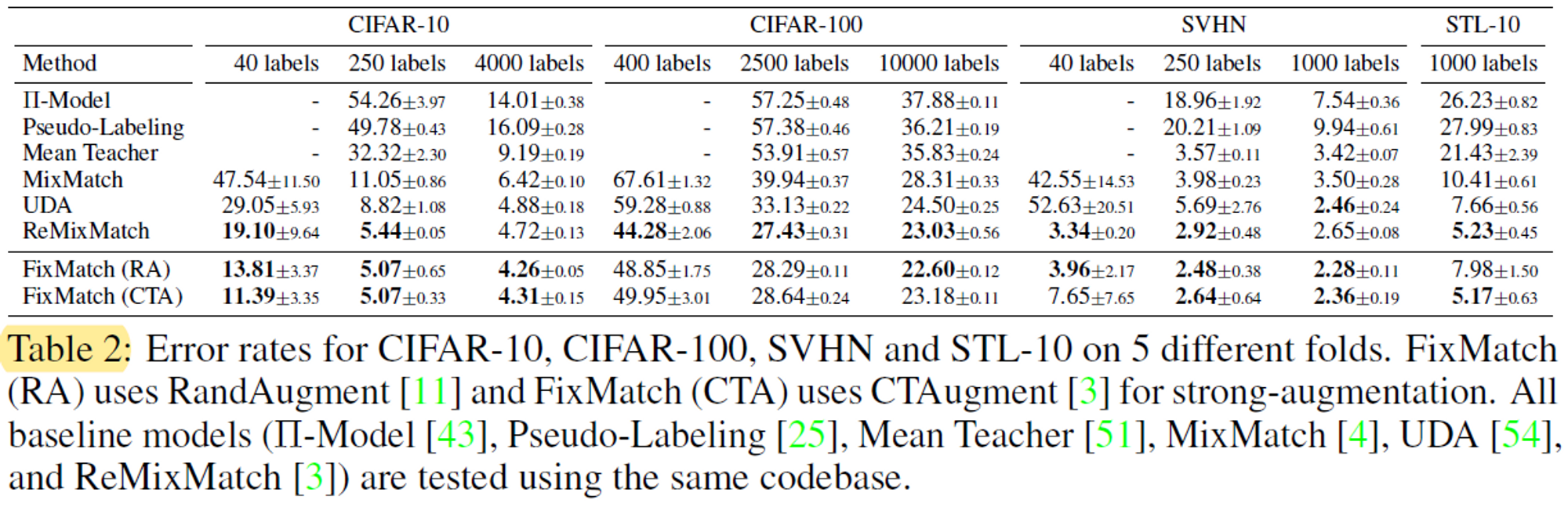
We report the performance of all baselines along with FixMatch
250개의 레이블에서 성능이 좋지 않았기 때문에
PYModel, Mean Teacher 및 Pseudo-Labeling에 대해 클래스당 4개의 레이블이 있는 결과를 생략한다.
MixMatch, ReMixMatch, UDA는 모두 40개와 250개의 레이블로 상당히 잘 작동하지만,
우리는 그럼에도 불구하고 FixMatch는 이러한 각 방법을 훨씬 능가하는 동시에 더 단순하다.
For example, FixMatch achieves an average error rate of 11.39% on CIFAR-10 with 4 labels per class.
우리 결과는 ReMixMatch가 약간 더 나은 성능을 발휘하는 CIFAR-100을 제외한 모든 데이터 세트에서 성능이 더 좋다.
ReMixMatch가 FixMatch보다 성능이 우수한 이유를 이해하기 위해 ReMixMatch의 다양한 구성 요소를 FixMatch에 복사하는 FixMatch의 몇 가지 변형을 실험했습니다.
우리는 가장 중요한 term이 분포 정렬(Distribution Alignment)이라는 것을 발견했는데,
이는 모델 예측이 레이블이 지정된 집합과 동일한 클래스 분포를 갖도록 장려한다.
>> 이건 ReMixMatch를 읽어봐야 알듯하다..!
FixMatch를 DA와 결합하면 레이블이 지정된 400개의 예제와 함께 40.14%의 오류율에 도달하며, 이는 ReMixMatch가 달성한 44.28%보다 훨씬 우수합니다.
>> 해당 논문 table에는 포함 안된 거 같은데 추후에 섞어서 연구한 듯
우리는 클래스당 4개의 레이블이 있는 설정을 제외하고 대부분의 경우
CTAugment와 RandAugment를 사용하는 FixMatch의 성능이 유사하다는 것을 발견했다.
분산으로 설명할 수가 있음.
예를 들어, 클래스당 4개의 레이블이 있는 CIFAR-10에 대한 5개의 서로 다른 접힘에 대한 분산은 3.35%로 클래스당 25개의 레이블(0.33%) 보다 훨씬 높습니다.
4.2 STL-10
The STL-10 dataset contains 5,000 labeled images of size 9696 from 10 classes and 100,000 unlabeled images.
As in table 2, FixMatch achieves the state-of-the-art performance of ReMixMatch despite being significantly simpler.
4.3 ImageNet
train 데이터의 10%를 레이블링 된 대로 사용하고 나머지는 레이블링 되지 않은 예로 취급한다.
FixMatch achieves a top-1 error rate of 28.54 ± 0.52%, which is 2.68% better than UDA.
Our top-5 error rate is 10.87 ± 0.28%.
4.4 Barely Supervised Learning
To test the limits of our proposed approach, we applied FixMatch to CIFAR-10 with only one example per class.
First, 클래스당 하나의 예제를 무작위로 선택하여 4개의 데이터 세트를 만든다.
우리는 각 데이터 세트에 대해 네 번 훈련하고 중앙값 64.28%로 48.58%와 85.32% 사이의 테스트 정확도에 도달한다.
그러나 데이터 세트 간 분산은 훨씬 낮다.
예를 들어 첫 번째 데이터 세트에 대해 훈련된 4개의 모델은 모두 61%에서 67%의 정확도에 도달하고
두 번째 데이터 세트는 68%에서 75% 사이에 도달한다.
우리는 이러한 가변성(일정한 조건에서 변할 수 있는 성질)이 각 데이터 세트를 구성하는 레이블이 지정된 10개의 예제의 품질에 의해 발생하며 낮은 품질의 예제를 샘플링하면 모델이 특정 클래스를 효과적으로 학습하는 것이 더 어려워질 수 있다고 가정한다.
이를 테스트하기 위해, 우리는 "원형성"(즉, 기본 클래스의 대표)에
이러한 예를 가진 8개의 새로운 훈련 데이터 세트를 구성한다.
구체적으로, 우리는 CIFAR-10 훈련 세트의 순서를 가장 대표적인 예에서 > 가장 적은 예로 정렬한다.
이 예제 순서는 모든 레이블이 지정된 데이터로 많은 CIFAR-10 모델을 교육한 후 결정되었다.
따라서 우리는 이것을 SSL에 사용할 예제를 선택하는 실용적인 방법으로 구상하지 않고,
보다 대표적인 예제가 낮은 레이블 훈련에 더 적합한지 실험적으로 검증한다.
이 순서를 8개의 버킷으로 균등하게 나눕니다
(따라서 가장 대표적인 예는 모두 첫 번째 버킷에 있고 마지막에 모든 특이치가 있음).
그런 다음 동일한 버킷에서 각 클래스의 레이블이 지정된 예제 하나를 무작위로 선택하여 8개의 레이블이 지정된 교육 세트를 생성한다.

동일한 하이퍼 매개 변수를 사용하여 대부분의 프로토타입 예제에 대해 훈련된 모델은 78% 정확도의 중앙값(최대 84% 정확도)에 도달하고 분포 중간에 대한 훈련은 65% 정확도에 도달하며 이상치에 대한 훈련만 10% 정확도로 완전히 수렴하지 못한다.
Figure 2는 FixMatch가 78%의 중앙값 정확도를 달성한 분할에 대한 전체 레이블 훈련 데이터 세트를 보여준다.
5. Ablation Study
we perform an extensive ablation study to better understand why it is able to obtain state-of-the-art results.
ablation study의 실험 수가 많기 때문에 CIFAR-10에서 250개의 레이블을 분할하여 연구하는 데 중점을 두고 CTAugment를 사용하여 결과만 보고한다.
기본 매개 변수를 사용하는 FixMatch는 이 특정 분할에서 4.84%의 오류율을 달성합니다.
5.1 Sharpening and Thresholding(선명도 및 임계값)
우리는 temperature T와 confidence threshold γ 사이의 상호 작용을 연구한다.
(a) 유사 레이블에 대한 신뢰 임계값 변경.
(b) 신뢰 임계값(γ)을 변경하면서 예측 레이블 분포를 "sharpening"하는 효과를 측정합니다.
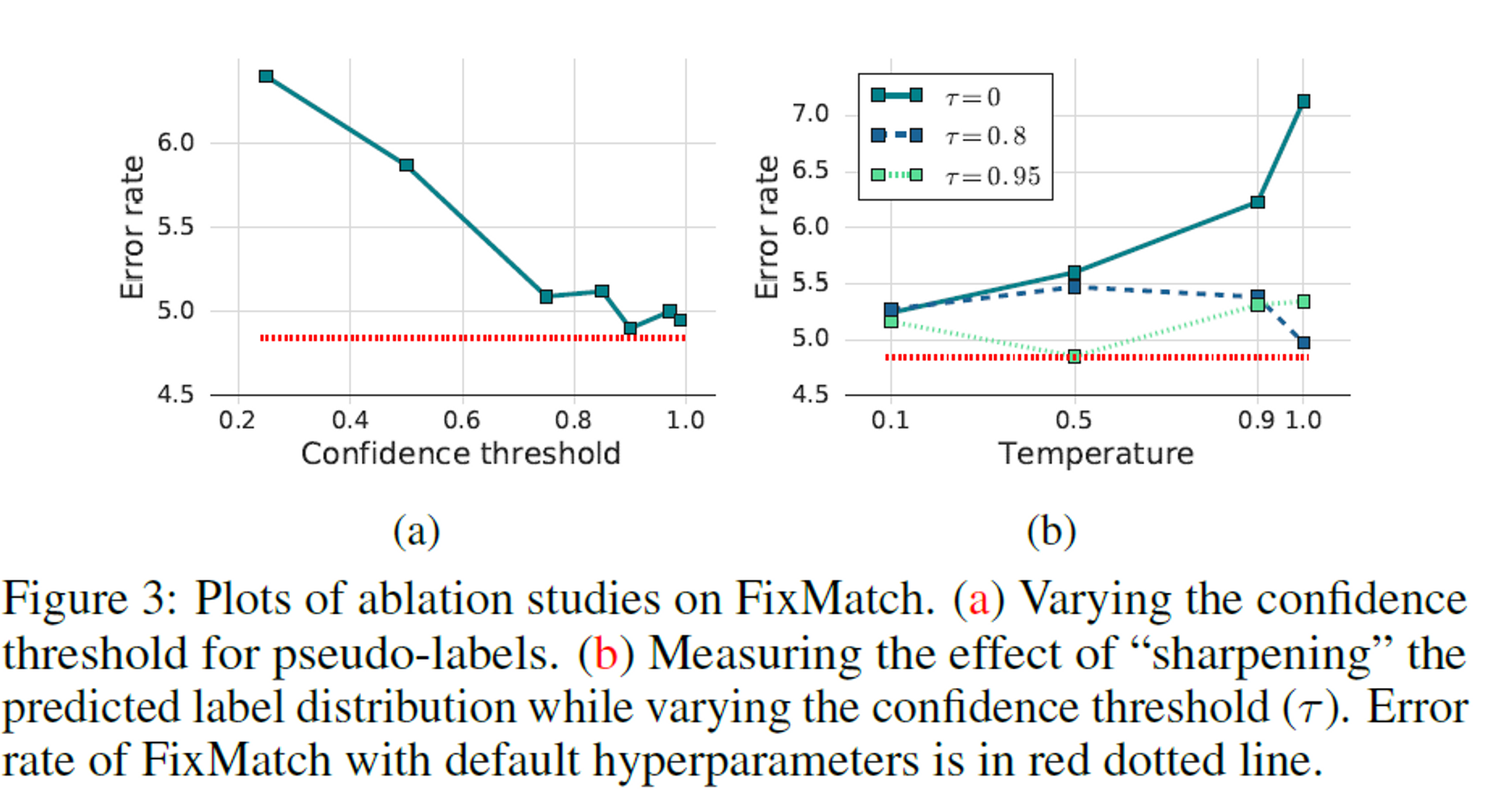
threshold 0.95는 오류율이 가장 낮지만 0.97 또는 0.99로 높이는 것은 큰 문제가 되지 않았다.
반면 작은 임계값을 사용하면 정확도가 1.5% 이상 떨어진다.
레이블이 지정되지 않은 데이터에 대한 pseudo-labels의 정확도는 임계값이 높을수록 증가하는 반면,
$l_u$에 기여하는 unlabeled data의 양은 감소한다.
>> 임계값이 높은 것만 pseudo-label로 바꾸니 데이터양이 감소할 수밖에 없음.
이는 높은 정확도에 도달하기 위해서는 양보다 유사 레이블의 품질이 더 중요하다는 것을 시사한다.
반면, Sharpening은 신뢰 임계값을 사용할 때 성능에 유의한 차이를 보이지 않았다.
요약하면, 우리는 Sharpening 및 임계값을 위해 “pseudo-labeling을 교환하는 것”이
더 나은 성능을 달성하지 못하면서 새로운 하이퍼 파라미터를 도입할 것이라는 것을 관찰한다.
>> Sharpening, 임계값을 위해 pseudo-labeling 교환하는 것이 의미가 없을 것이다라고 말하는 것 같음
5.2 Augmentation Strategy
We conduct an ablation study on different strong data augmentation policies as it plays a key role in FixMatch.
Specifically, we chose RandAugment and CTAugment, which have been used for SOTA SSL algorithms
such as UDA and ReMixMatch respectively.
On CIFAR-10, CIFAR-100, and SVHN we observed highly comparable results between the two policies,
whereas in STL-10 (table 2), we observe a significant gain by using CTAugment.
>> STL-10에서는 CTAugment방법이 더 잘 적용된 것으로 보인다.

We measure the effect of Cutout
>> Cutout이라는 augmentation 방법이 있는 듯
우리는 RandAugment와 CTAugment 모두에서 strong augmentation 후
기본적으로 사용되는 table 3에서 Cutout의 효과를 측정한다.
우리는 최고의 성능을 얻으려면 Cutout과 CTAugment가 모두 필요하다는 것을 발견했다.
둘 중 하나를 제거하면 error rate가 크게 증가한다.
우리는 또한 pseudo-label 생성 및 예측을 위해 weak and strong augmentations의 다른 조합을 연구한다.
라벨 추측을 위한 약한 증강을 강한 증강으로 대체했을 때, 우리는 모델이 훈련 초기에 분기되었다는 것을 발견했다.
반대로, 약한 증강을 증강 없이 대체할 때 모델은 추정된 레이블이 없는 레이블을 과도하게 적합시킨다.
또한 강력한 증강 대신 약한 증강을 사용하여 훈련에 대한 모델의 예측을 생성하는 것은
45% 정확도에서 정점을 찍었지만 안정적이지 않았고 12%로 점진적으로 붕괴되어 강력한 데이터 증강의 중요성을 시사했다.
>> 즉, 해당논문 설정과 다르게 바꾸면 안 좋게 나온다
6. Conclusion
We introduce FixMatch, a simpler SSL algorithm that achieves state-of-the-art results across many datasets.
We show how FixMatch can begin to bridge the gap between low-label semi-supervised learning and few-shot learning or clustering
>> labeled data를 적게 사용했다는 관점에서 few-shot learning연구와 관련이 있어 보인다.
, semi와 few-shot을 관련짓기 위해서 이러한 관점도 괜찮겠다는 생각이 들었음..
, 간단한 수식, 아이디어로 높은 성능을 보여준 관점으로써 매우 대단해 보인다.
, code도 간단하다고 함
논문에서 말하기를 가장 중요한 건 weight decay와 choice of optimizer이라고 한다.
즉 certain 한 design을 잘 선택하는 것이 중요하다고 한다.
따라서 model architecture을 제어하는 경우에도, same technique가 항상 다른 implementation 간에 직접 비교될 수는 없다는 것을 의미한다.
'Main > Paper Review' 카테고리의 다른 글
| [Paper Review] LWF: Learning Without Forgetting (0) | 2022.12.19 |
|---|---|
| [Paper Review] Transformer: Attention Is All You Need (0) | 2022.07.12 |
| [Paper Review] MobileNet V1 (0) | 2022.05.26 |
| [Paper Review] SENet: Squeeze-and-Excitation Networks (0) | 2022.05.16 |
| [Paper Review] Batch Normalization (1) | 2022.03.31 |




댓글