"LWF: Learning Without Forgetting"
논문 리뷰입니다.
https://arxiv.org/abs/1606.09282
해당 논문은 ECCV 2016에 실린 초창기 Continual Learning에 관한 논문입니다.
목차
LWF Introduction

해당 논문은 새로운 task에 대해서 Continual 한 상황에서 학습하는 방법을 제안합니다.
우리의 목적은 new task와 old task의 parameters를 공유하면서 forgetting 하지 않고 old task을 학습하기를 원합니다.
즉, LWF는 Distillation network와 Fine-Tuning을 결합한 것입니다.

논문을 이해하기 위해서, 몇 가지 parameters를 정의할 필요가 있습니다.
- Shared parameters: θs: (ex. five convolutional layers and two fully connected layers for ‘AlexNet’ architecture)
- Task-specific parameters for previously learned tasks: θo: (ex. the output layer for ImageNet classification and corresponding weights)
- Randomly initialized task specific parameters for new tasks: θn: (ex. scene classifiers)
Compared Methods

해당 table을 통해 LWF Method를 제외한 나머지 Methods에서 한 개 이상의 drawback이 있는 것을 알 수 있습니다.
Drawbacks of Methods

그림에 나와있는 architecture을 보면, box color에 따라 어떤 parameters가 leraned and not learned 되는지 확인할 수 있습니다.
따라서,
orenge box means random initialize + train, blue box means fine - tuning, white box means unchanged.
1. Feature Extraction
먼저, Feature Extraction을 new task에 있어서 underperform을 보여줍니다.
왜냐하면 θs와 θo이 unchanged 하기 때문입니다.
따라서, θs는 new task의 일부 정보들을 대표하지 못합니다.
2. Fine-tuning
Fine-tuning에서는 θs와 θn이 new task에 있어서 최적화되지만, θo 은 unchanged 합니다.
따라서, Fine-tuning은 previously learned tasks의 performance를 하락시킵니다.
왜냐하면 θo의 guidance 없이 θs가 change 하기 때문입니다.

3. Joint Training
Joint Training은 Multitask Learning이라는 용어랑 같은 말입니다.
Joint Training은 모든 task들을 simultaneously 하게 training 하는 것을 목표로 합니다.
따라서, 모든 parameters θs, θo, θn들이 jointly optimized 됩니다.
Joint Training은 더 많은 작업이 학습됨에 따라 training에서 점점 더 번거로워지고 이전에 학습된 작업에 대한 training data를 사용할 수 없는 경우에는 불가능합니다.
4. Learning without Forgetting
우리의 모델 LWF는 all parameters가 학습되었음을 알 수 있습니다.
LWF는 Joint training과 매우 유사한 모델입니다.
하지만, 차이점이 있습니다.
Main difference는 old dataset의 필요성입니다.
Joint Training은 Training에서 old task의 images와 labels를 사용하지만, LWF는 더 이상 old task의 images와 labels를 사용하지 않습니다.
response는 각 train image에 대한 label probabilities의 집합입니다.
여기서 response를 사용한다는 것이 생소한데 Knowledge Distillation의 개념이 사용됩니다.
Knowledge Distillation는 Teacher모델의 response를 학습에 사용해서 Student의 성능을 끌어올리는 것이라고 할 수 있습니다.
Learning Without Forgetting

LWF는 new task에 대한 task-specitic parematers(θn)를 추가합니다.
또한 new task의 images와 labels만 사용하여 old task와 new task에서 잘 작동하는 parameters를 학습합니다.

LWF 개요입니다.
LWF는 new task images Xn과 responses Yo을 substitutes로 사용합니다.
Yo을 사용하면 old dataset을 요구하고 저장할 필요가 없습니다.
또한 공유된 θs의 공동 최적화 이점을 같이 제공합니다.
θs, θo, θn을 최적화 하기 위해서,해당 손실 함수를 사용합니다.
lamda is loss balance weight.
if lamda increase, result is favor the old task performance.
old task loss function using the modified cross entropy loss. > Distillation 개념
new task loss function using the cross-entropy loass.
regular term is weight decay.
Loss function을 자세하게 살펴보겠습니다.
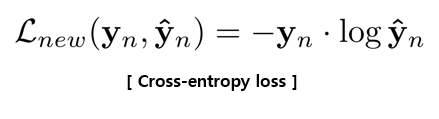
이 term은 predictions Y^n (softmax output)이 ground truth Yn ( one-hot ground truth label vector)과 일치하도록 장려합니다.

old task에 대한 knowledge를 유지하기 위해 Distillation을 적용합니다.
이것은 더 작은 확률에 대한 가중치를 증가시키는 modified cross-entropy loss입니다.
T(Temperature): Scaling 역할의 Hyperparameter
- T=1일 때, 기존 softmax function과 동일
- T 클수록, 더 soft 한 확률분포
논문에서 Hinton은 T > 1로 설정하는 것을 제안합니다.
이는 smaller logit values의 가중치를 증가시키고 네트워크가 클래스 간의 similarities( 유사성 )을 더 잘 인코딩하도록 장려합니다.
Experiment - Single New Task Scenario
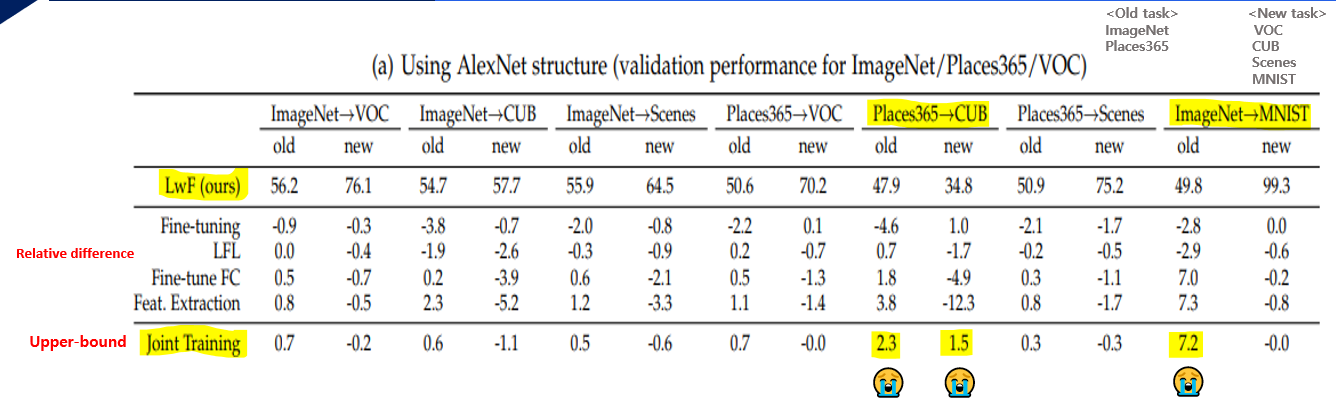
예를 들어, 이 실험은 Single New Task Scenario를 사용합니다.
모든 테이블에 대해 LWF와의 difference of methods가 비교를 용이하게 하는 것으로 보고되었습니다.
우리는 또한 Joint Training을 upper-bound on possible old task performance로 비교합니다.
왜냐하면, joint training은 original and new tasks에 images and labels을 사용하지만 LwF는 only images and labels for the new tasks.
우리의 방법은 outperforms fine-tuning, Feature extraction and joint training보다 약간 낮은 성능을 달성합니다.
Places365 > CUB, ImageNet > MNIST로의 작업은 old task에서 제대로 수행되지 않기 때문에 예외입니다.
왜냐면, MNIST는 손으로 쓴 문자로 ImageNet 클래스와 관련이 없습니다.
그리고 CUB는 새 그림이기 때문에 places365(장소)와 관련이 없습니다.
참고자료
https://gbjeong96.tistory.com/40?category=976894
[논문리뷰] Learning Without Forgetting(ECCV 2016)
해당 논문은 ECCV 2016에 실린 초창기 Continual learning에 관한 paper이다. 해당 논문은 새로운 task에 대해서 Continual한 상황에서 학습하는 방법을 제안한다. 이때 여러가지 방법을 사용할 수 있는데 기
gbjeong96.tistory.com
https://ffighting.tistory.com/94
[PAML 2017] Learning Without Forgetting (LwF) 핵심 리뷰
내용 요약 LwF(Learning-Without-Forgetting) 방식의 Incremental Learning 방법론을 제안합니다. Cross Entropy Loss와 Softmax 출력층에 Distillation Loss를 적용했습니다. 안녕하세요. 오늘은 PAML 2017 논문인 Learning Without
ffighting.tistory.com
'Main > Paper Review' 카테고리의 다른 글
| [Paper Review] FixMatch: Simplifying Semi-Supervised Learningwith Consistency and Confidence (0) | 2023.03.17 |
|---|---|
| [Paper Review] Transformer: Attention Is All You Need (0) | 2022.07.12 |
| [Paper Review] MobileNet V1 (0) | 2022.05.26 |
| [Paper Review] SENet: Squeeze-and-Excitation Networks (0) | 2022.05.16 |
| [Paper Review] Batch Normalization (1) | 2022.03.31 |




댓글