본 내용은 'Python ML Perfect Guied' 서적을 바탕으로 학습하기 위해 작성하였습니다.
목차
- 앙상블 학습(Ensemble Learning) 이란?
- 앙상블 학습(Ensemble Learning)의 특징
- 앙상블 학습(Ensemble Learning)의 유형
- 보팅(Voting)
- 하드 보팅(Hard Voting)
- 소프트 보팅(Soft Voting)
- 배깅(Bagging)
- 랜덤 포레스트(Random Forest)
- 부스팅(Boosting)
- AdaBoost
- GBM(Gradient Boosting Machine)
- 보팅(Voting)
앙상블 학습(Ensemble Learning) 이란?
여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법을 말합니다.
예를 들어 어려운 문제의 결론을 내기 위해 여러 명의 전문가로 위원회를 구성해 다양한 의견을 수렴하고 결정하듯이 앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것입니다.
앙상블 학습(Ensemble Learning)의 특징
- 단일 모델의 약점을 다수의 모델들을 결합하여 보완
- 뛰어난 성능을 가진 모델들로만 구성하는 것보다 성능이 떨어지더라도 서로 다른 유형의 모델을 섞는 것이 오히려 전체 성능이 도움이 될 수 있음.
- 랜덤 포레스트 및 뛰어난 부스팅 알고리즘들을 모두 결정 트리 알고리즘을 기반 알고리즘으로 적용함
- 결정 트리의 단점인 과적합(Over fitting)을 수십 ~ 수천 개의 많은 분류기를 결합해 보완하고 장점인 직관적인 분류 기준은 강화됨
앙상블 학습(Ensemble Learning)의 유형
일반적으로는 보팅(Voting), 배깅(Bagging), 부스팅(Boosting)으로 구분할 수 있으며, 이외에 스태킹 등의 기법이 있습니다. 보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식입니다.
- 보팅(Voting)

위 그림은 보팅 분류기를 도식화한 것입니다. 결정 트리, K 최근접 이웃, 로지스틱 회귀라는 3개의 서로 다른 ML알고리즘이 같은 데이터 세트에 대해 학습하고 예측한 결과를 가지고 보팅을 통해 최종 예측 결과를 산정하는 방식입니다.
보팅(Voting) 방법에는 두 가지가 있습니다.
1. 하드 보팅(Hard Voting)
예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정하는 것입니다.
다수결 원칙과 비슷합니다.
2. 소프트 보팅(Soft Voting)
분류기의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정합니다. 일반적으로 소프트 보팅이 보팅 방법으로 적용됩니다.
사이킷런은 보팅 방식의 앙상블을 구현한 VotingClassfier 클래스를 제공하고 있습니다.
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
data_df.head(3)로지스틱 회귀와 KNN을 기반으로 하여 소프트 보팅 방식으로 새롭게 보팅 분류기를 만들어 보겠습니다.
VotingClassifier 클래스는 주요 생성 인자로 estimators(복수)와 voting 값을 입력받습니다. estimators는 리스트 값으로 보팅에 사용될 여러 개의 Classfier 객체들을 튜플 형식으로 입력받으며 voting은 'hard'시 하드 보팅, 'soft'시 소프트 보팅 방식을 적용하라는 의미입니다. (기본은 'hard' 입니다.)
# 개별 모델은 로지스틱 회귀와 KNN 임.
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier( estimators=[('LR',lr_clf),('KNN',knn_clf)] , voting='soft' )
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
test_size=0.2 , random_state= 156)
# VotingClassifier 학습/예측/평가.
vo_clf.fit(X_train , y_train)
pred = vo_clf.predict(X_test)
print('Voting 분류기 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
# 개별 모델의 학습/예측/평가.
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train , y_train)
pred = classifier.predict(X_test)
class_name= classifier.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test , pred)))
보팅 분류기가 정확도가 조금 높게 나왔는데, 보팅으로 여러 개의 기반 분류기를 결합한다고 해서 무조건 기반 분류기보다 예측 성능이 향상되지는 않습니다. 데이터의 특성과 분포 등 다양한 요건에 따라 오히려 기반 분류기 중 가장 좋은 분류기의 성능이 보팅 했을 때보다 나을 수도 있습니다.
그럼에도 불구하고 지금 소개하는 보팅을 포함해 부스팅 등의 앙상블 방법은 전반적으로 다른 단일 ML 알고리즘보다 뛰어난 예측 성능을 가지는 경우가 많습니다. 다양한 관점을 가진 알고리즘이 서로 결합해 더 나은 성능을 실제 환경에서 끌어낼 수 있습니다.
- 배깅(Bagging)
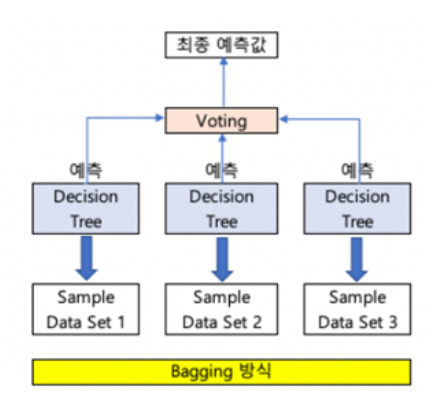
배깅 분류기를 도식화한 것입니다. 단일 ML 알고리즘(결정 트리)으로 여러 분류기가 학습으로 개별 예측을 하는데, 학습하는 데이터 세트가 보팅 방식과는 다릅니다. 개별 분류기에 할당된 학습 데이터는 원본 학습 데이터를 샘플링해 추출하는데, 이렇게 개별 Classfier에게 데이터를 샘플링해서 추출하는 방식을 Bootstrapping 분할 방식이라고 부릅니다.
즉, 개별 분류기가 Bootstrapping 분할 방식으로 샘플링된 데이터 세트에 대해서 학습을 통해 개별적인 예측을 수행한 결과를 보팅을 통해서 최종 예측 결과를 선정하는 방식이 바로 배깅(Bagging) 앙상블 방식입니다.
대표적인 알고리즘은 랜덤 포레스트가 있습니다.
1. 랜덤 포레스트(Random Forest)
다재다능한 알고리즘입니다. 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있으며, 다양한 영역에서 높은 예측 성능을 보이고 있습니다.
여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 하게 됩니다.
- 랜덤 포레스트의 Bootstrapping 분할
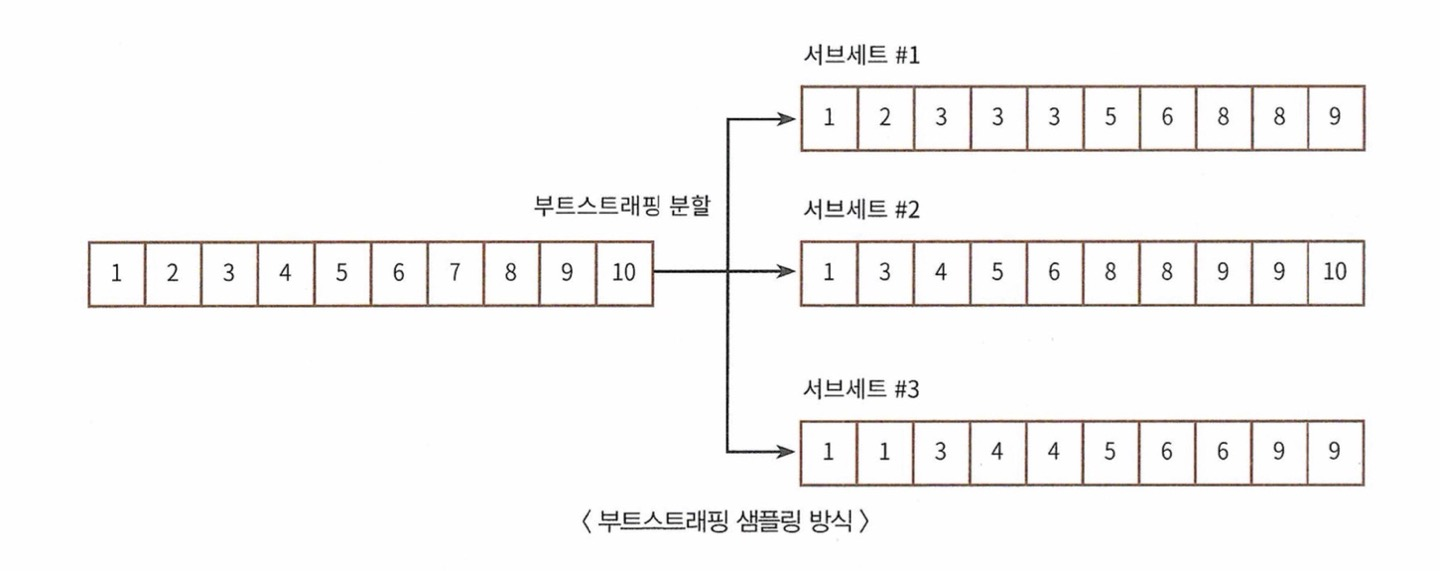
- 랜덤 포레스트는 개별적인 분류기의 기반 알고리즘은 결정 트리이지만 개별 트리가 학습하는 데이터 세트는 전체 데이터에서 일부가 중첩되게 샘플링된 데이터 세트입니다. 이렇게 여러 개의 데이터 세트를 중첩되게 분리하는 것을 부트 스트래핑(bootstrapping) 분할 방식이라고 합니다. ( 그래서 Bagging이 bootstrap aggregating의 줄임말입니다.)
- 원본 데이터 개수가 10개인 학습 데이터 세트에 랜덤 포레스트를 3개의 결정 트리 기반으로 학습하려고 n_estimators=3으로 하이퍼 파라미터를 부여한다면 다음과 같이 데이터 서브 세트가 만들어집니다.
- 랜덤 포레스트 하이퍼 파라미터 및 튜닝
트리 기반의 앙상블 알고리즘의 단점을 굳이 뽑자면 하이퍼 파라미터가 너무 많고, 그로 인해서 튜닝을 위한 시간이 많이 소모된다는 것입니다. 더구나 많은 시간을 소모했음에도 튜닝 후 예측 성능이 크게 향상되는 경우가 많지 않아서 더욱 아쉽습니다.
- n_estimators: 랜덤 포레스트에서 결정 트리의 개수를 지정합니다. default는 10개입니다. 많이 설정할수록 좋은 성능을 기대할 수 있지만 계속 증가시킨다고 성능이 무조건 향상되는 것은 아닙니다.
- max_features는 결정 트리에 사용된 max_features 파라미터와 같습니다. 하지만 RandomForestClassifier의 기본 max_features는 'None'이 아니라 'auto'. 즉 'squt'와 같습니다. 따라서 랜덤 포레스트의 트리를 분할하는 피처를 참조할 때 전체 피처가 아니라 sqrt(전체 피처 개수)만큼 참조합니다. (전체 피처가 16개라면 분할을 위해 4개 참조)
- GridSearchCV 로 교차검증 및 하이퍼 파라미터 튜닝
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
max_depth 4개, min_samples_leaf 3개, min_samples_split 3개 각 경우의 수를 곱하면 36번이고
여기에 cv 수를 곱하면 72이므로 총 72번을 진행합니다.
n_jobs = -1 파라미터를 추가하면 모든 CPU 코어를 이용해 학습할 수 있습니다.
rf_clf1 = RandomForestClassifier(n_estimators=300, max_depth=10, min_samples_leaf=8, \
min_samples_split=8, random_state=0)
rf_clf1.fit(X_train , y_train)
pred = rf_clf1.predict(X_test)
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
- 부스팅(Boosting)
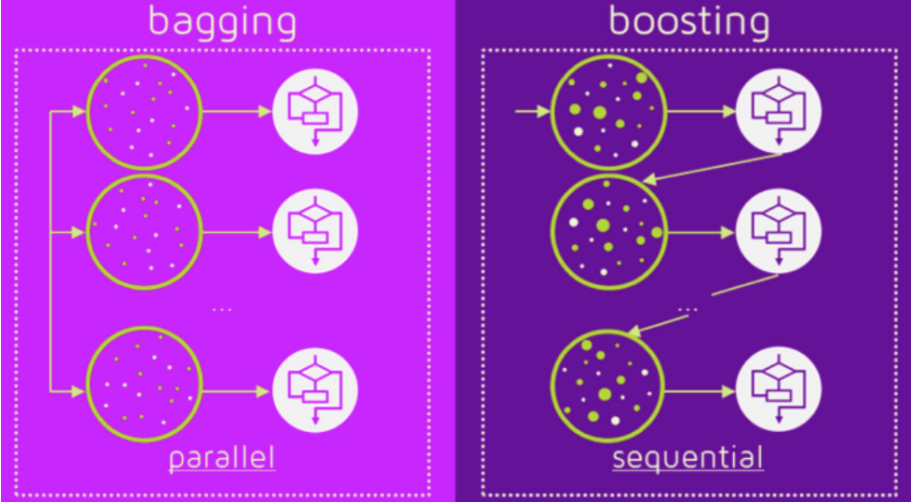
여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 다음 분류기에게는 가중치(weight)를 부여하면서 학습과 예측을 진행하는 것입니다.
계속해서 분류기에게 가중치를 부스팅 하면서 학습을 진행하기에 부스팅 방식으로 불립니다.
예측 성능이 뛰어나 앙상블 학습을 주도하고 있으며 대표적인 부스팅 모델로 그래디언트 부스트, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost)이 있습니다.
1. AdaBoost
부스팅의 대표적인 구현중 하나인 AdaBoost는 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘입니다.
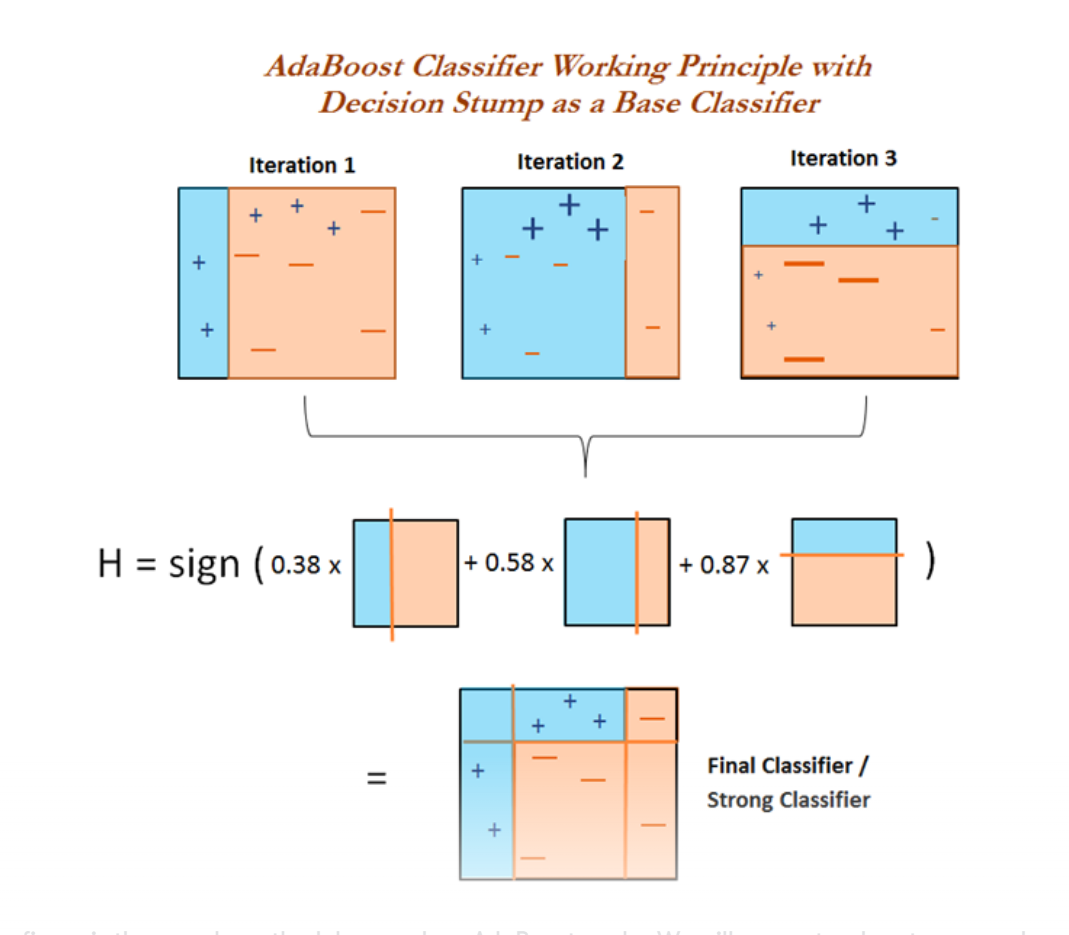
맨 아래에는 첫 번째, 두 번째, 세 번째 약한 학습기를 모두 결합한 결과 예측입니다. 개별 약한 학습기보다 훨씬 정확도가 높아졌음을 알 수 있습니다.
2. GBM(Gradient Boosting Machine)
AdaBoost와 유사하나, 가중치 업데이트를 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이입니다. 이 경사 하강법은 머신러닝에서 중요한 기법 중 하나입니다. 경사 하강법 개념은 따로 글을 작성하여 공유하도록 하겠습니다.
여기서는 '반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법'정도로만 이해해도 좋을 것 같습니다.
사이킷런은 GBM 기반의 분류를 통해서 GradientBoostingClassifier 클래스를 제공합니다.
from sklearn.ensemble import GradientBoostingClassifier
import time
import warnings
warnings.filterwarnings('ignore')
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train , y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간: {0:.1f} 초 ".format(time.time() - start_time))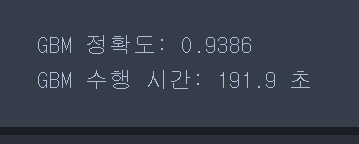
기본 하이퍼 파라미터만으로 93.86%의 예측 정확도로 앞의 랜덤 포레스트보다 나은 예측 성능을 나타냈습니다.
일반적으로 GBM이 랜덤 포레스트보다는 예측 성능이 조금 뛰어난 경우가 많습니다. 그러나 수행 시간이 오래 걸리고, 하이퍼 파라미터 튜닝 노력도 더 필요합니다.
- GridSearchCV 로 하이퍼 파라미터 튜닝
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100, 500],
'learning_rate' : [ 0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf , param_grid=params , cv=2 ,verbose=1)
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
scores_df = pd.DataFrame(grid_cv.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score',
'split0_test_score', 'split1_test_score']]
# GridSearchCV를 이용하여 최적으로 학습된 estimator로 predict 수행.
gb_pred = grid_cv.best_estimator_.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))- loss: 경서 하강법에서 사용할 비용 함수를 지정합니다. 특별한 이유가 없으면 기본값인 'deviance'를 그대로 사용합니다.
- learning_rate: GBM이 학습을 진행할 때마다 적용하는 학습률입니다. 0~1 사이의 값을 지정할 수 있으며 기본값은 0.1입니다.

GBM은 과적합에도 강한 뛰어난 예측 성능을 가진 알고리즘입니다. 하지만 수행 시간이 오래 걸린다는 단점이 있습니다.
※ 트리 기반의 앙상블 학습에서 가장 각광받고 알고리즘 중 XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost) 알고리즘이 있습니다.
해당 알고리즘에 대해서는 내용도 방대할 뿐만 아니라 하이퍼 파라미터에 관한 내용도 많아서
따로 글을 작성하여 공유하도록 하겠습니다. ※
'Main > Machine Learning' 카테고리의 다른 글
| [ML - lec 07] ML의 실용과 몇 가지 팁 (0) | 2022.03.13 |
|---|---|
| [ML - lec 06] Softmax Regression (Multinomial Logistic Regression) (0) | 2022.03.13 |
| [ML - lec 05] Logistic (Regression) Classification (0) | 2022.03.06 |
| [ML - lec 04] Multi-variable linear regression (0) | 2022.03.06 |
| [ML - lec 02,03] Linear Regression의 Hypothesis와 cost (0) | 2022.03.06 |




댓글