본 내용은 김성훈 교수님의 '모두를 위한 딥러닝' 강의와
https://pythonkim.tistory.com/notice/25 를 참고하여 제작하였습니다.
목차
- 용어 정리
- What hypothesis is better?
- Cost function
- Cost 최소화 알고리즘의 원리 설명
- Gradient descent algorithm
용어 정리
본 강좌 내용을 학습하기에 앞서서 먼저 몇 가지 용어에 대한 정리가 필요합니다.
1. 회귀분석
점들이 퍼져있는 형태에서 패턴을 찾아내고, 이 패턴을 활용해서 무언가를 예측하는 분석. 새로운 표본을 뽑았을 때 평균으로 돌아가려는 특징이 있기 때문에 붙은 이름. 회귀(回歸 돌 회, 돌아갈 귀)라는 용어는 일반적으로 '돌아간다'는 정도로만 사용하기 때문에 회귀로부터 '예측'이라는 단어를 떠올리기는 쉽지 않습니다.
2. Linear Regression
2차원 좌표에 분포된 데이터를 1차원 직선 방정식을 통해 표현되지 않은 데이터를 예측하기 위한 분석 모델. 머신러닝 입문에서는 기본적으로 2차원이나 3차원까지만 정리하면 됩니다. 여기서는 편의상 1차원 직선으로 정리하고 있습니다. xy 축 좌표계에서 직선을 그렸다고 생각하면 됩니다.
3. Hypothesis
Linear Regression에서 사용하는 1차원 방정식을 가리키는 용어로, 우리말로는 가설이라고 합니다. 수식에서는 h(x) 또는 H(x)로 표현합니다.
H(x) = Wx + b에서 Wx + b는 x에 대한 1차 방적식으로 직선을 표현한다는 것은 모두 알 것이고, 기울기에 해당하는 W(Weight)와 절편에 해당하는 b(bias)가 반복되는 과정에서 계속 바뀌고, 마지막 루프에서 바뀐 최종 값을 사용해서 데이터 예측(prediction)에 사용하게 됩니다. 최종 결과로 나온 가설을 모델(model)이라고 부르고, "학습되었다"라고 합니다. 학습된 모델은 배포되어서 새로운 학습을 통해 수정되기 전까지 지속적으로 활용됩니다.
4. Cost (비용)
앞에서 설명한 Hypothesis 방정식에 대한 비용(cost)으로 방정식의 결과가 크게 나오면 좋지 않다고 얘기하고, 루프를 돌 때마다 W와 b를 비용이 적게 발생하는 방향으로 수정하게 됩니다.
놀랍게도 미분이라는 수학 공식을 통해 스스로 최저 비용을 찾아가는 마술 같은 경험을 하게 될 것입니다.
5. Cost 함수
Hypothesis 방정식을 포함하는 계산식으로, 현재의 기울기(W)와 절편(b)에 대해 비용을 계산해 주는 함수입니다. 매번 호출할 때마다 반환 값으로 표현되는 비용이 줄어들도록 코딩되어야 합니다. 여기서는 Linear Regression에서 최소 비용을 검색하기 위한 역할을 담당합니다.
What hypothesis is better?

일단 우리는 Hypothesis가 1차 방정식이 될 것이다라고 가설을 세우는 것이 Linear Regression의 첫 번째 단계가 될 것입니다. 그러면 W(Weight)와 절편에 해당하는 b(bias)에 따라 달라지는 선들이 나타나겠죠.
그러면 이렇게 나타난 선들 중에서 어떤 선이 가장 잘 맞는 선일 까요??
가장 기본적인 것은 어떤 '선 or모델 or가설'이 좋은 것인지 찾을 때
실제 데이터와 이 가설이 나타내는 data 값들과의 거리를 비교해서 그 거리가 멀면 나쁜 거고 가까운 거면 좋은 것이라는 것을 찾으면 됩니다.
직선으로부터 각각의 데이터(좌표)까지의 거리 합계를 계산한 것을 cost라고 부르고, 이 값이 가장 작은 직선을 찾으면 목표 달성입니다.
Cost function
Hypothesis 방정식을 포함하는 계산식으로, 현재의 기울기(W)와 절편(b)에 대해 비용을 계산해 주는 함수입니다. 매번 호출할 때마다 반환 값으로 표현되는 비용이 줄어들도록 코딩되어야 합니다. 여기서는 Linear Regression에서 최소 비용을 검색하기 위한 역할을 담당합니다.
해당 그림에서 y를 빼는 행위에는 H(x)에 포함된 모든 x만큼의 계산이 포함되어 있습니다. 즉, 뺄셈 1회가 아니라 3회를 하게 됩니다.
수식이 조금 복잡해 보이죠? H(X(1)) - y(1)이라고 하는 표현식은 x의 1번째 데이터를 입력했을 때의 방정식(Hypothesis) 결과에서 y의 1번째 데이터를 뺐다는 뜻입니다.
그렇다면, 왜 Hypothesis의 결과에서 y를 뺀 다음에 제곱을 하는 것일까요?
1. 뺄셈을 하게 되면 직선 위치에 따라 음수와 양수가 섞여서 나오게 됩니다.
2. 절댓값을 취하는 것이 가장 쉽지만, 제곱을 하는 것도 방법입니다. (음수 x음수)와 (양수 x양수)에 대해 항상 양수가 나옵니다.
3. 제곱을 하면 가까운 데이터는 작은 값이 나오고, 멀리 있는 데이터는 큰 값이 나오기 대문에 멀리 있는 데이터에 벌점(penalty)을 부과할 수 있습니다.
최종적으로 좌표의 개수만큼 나누는 이유는 데이터 양이 많아지게 되면 엄청나게 값이 커지게 되고 계산이 복잡해 지기 때문에 나눕니다.
앞에서 거리의 제곱을 취한다고 얘기했는데, 이 방법을 LSM(Least Square Method)이라고 부릅니다. 통계학 관련 서적에 보면, 절댓값을 이용한 처리보다 튼튼(robust)하다고 알려져 있습니다.
앞에서 설명했던 공식들을 다시 정리하고 있습니다. 데이터까지의 합계를 m으로 나눈 결과는 해당 Hypothesis에 대한 cost(비용)입니다. 목표는 cost를 최소로 만드는 W( 기울기)와 b(절편)를 찾는 것입니다.
cost(W, b)로 시작하는 공식을 보면, 실제로는 W와 b가 보이지 않습니다. H(x) 안에 숨어있기 때문입니다.
Cost 최소화 알고리즘의 원리 설명
정말 중요한 Gradient descent 알고리즘에 대한 설명이 나옵니다!
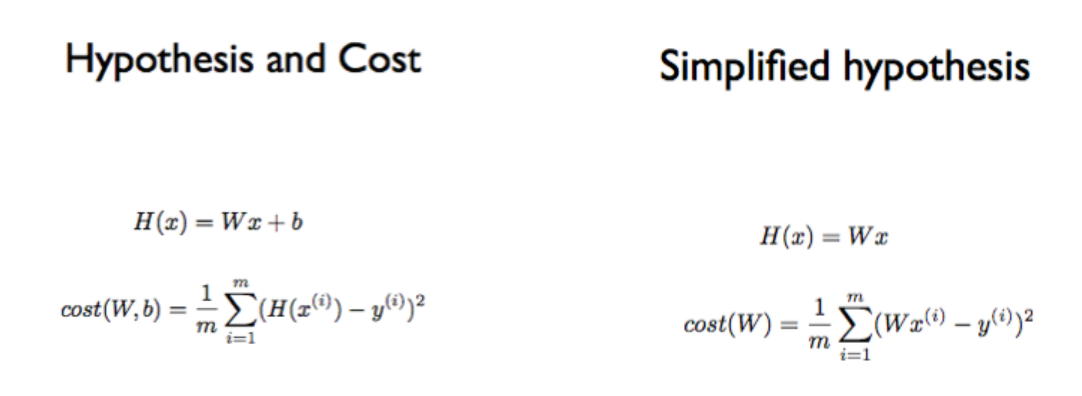
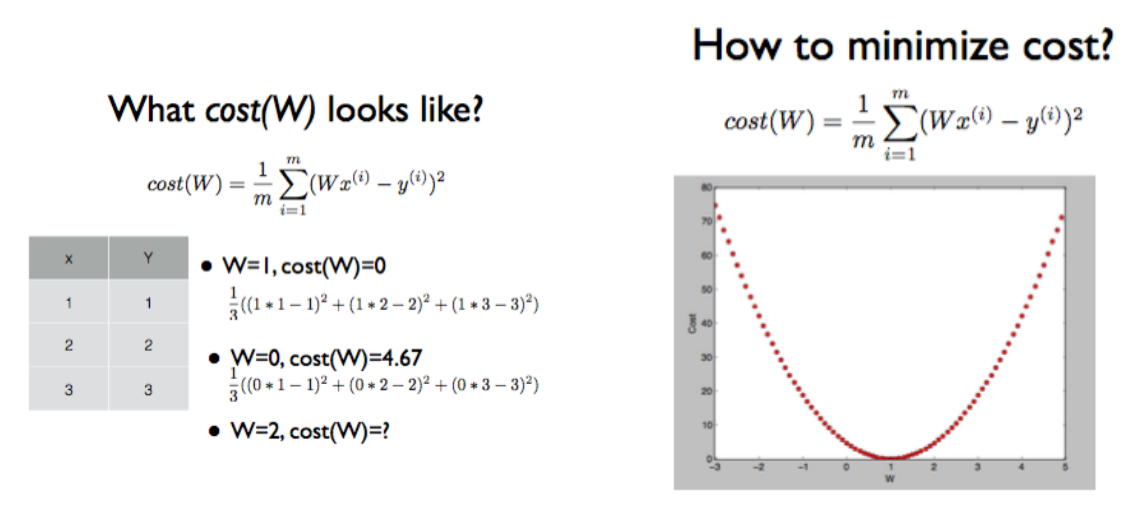
b를 없앤 단순 버전의 공식에 대해 실제 데이터인 x, y를 직접 대입해서 cost를 계산해 봅니다.
오른쪽 그림은 왼쪽에서 계산한 공식이 반복된 경우를 가정한 그래프입니다.
여기서 우리의 목표는 cost가 최소가 되는 값을 찾는 것입니다. 즉, 현재 데이터에서는 W가 1일 때 가장 작은 비용이 듭니다.
W가 1이라는 것은 H(x) = X라는 뜻이고, x에 대한 y 좌표가 정확하게 일치하기 때문에 cost는 0이 된다. 다시 말해, 이것보다 작은 비용이 발생할 수는 없으므로, 현재 구한 기울기(W)가 가장 적합하다는 뜻이 된다.
1. Gradient descent algorithm

최솟값을 기계적으로 찾기 위해 많이 사용되는 알고리즘이 Gradient descent algorithm(경사 하강법)입니다.
Gradient Descent 알고리즘은 그림에 있는 설명처럼 다음과 같은 역할을 수행한다.
1. 최저 비용을 계산하는 함수
2. 다양한 최저 계산에 사용
3. Cost 함수에 대해 최소가 되는 기울기(W)와 y 절편(b) 탐색
4. 피처(feature, 변수)가 여러 개인 버전에도 적용 가능
위의 설명을 다시 정리해 보면, 다음과 같다.
1. 어떤 위치(왼쪽 또는 오른쪽 경사)에서 시작하더라도 최소 비용 계산
2. 기울기(W)와 y 절편( b)을 계속적으로 변경하면서 최소 비용 계산
3. 반복할 때마다 다음번 gradients(기울기의 정도) 계산 - 미분
4. 최소 비용에 수렴(converge)할 때까지 반복
여러분들이 만약에 한라산 등산을 하고 있습니다. 해가지고 있는 와중에 길을 잃어 빨리 내려가야 하는 상황입니다. 여러분들은 어떻게 내려오시겠습니까?
간단한 질문이지만, 여러분들이 서있는 지점에서 경사가 있는 지점으로 한 발짝 내딛을 것이고 이 과정을 반복하다 보면 가장 낮은 곳으로 내려올 수 있겠죠.
기울기의 정도를 계산하기 위해서는 미분이 필요합니다.

Formal definition에서 m으로 나누건 2m으로 나누건 W와 b에는 영향을 주지 않는다는 것을 먼저 이해해야 합니다. 비용 계산의 목적은 최소 비용이 되었을 때의 W와 b가 필요하기 때문입니다. 최소 비용이 얼마인지는 전혀 중요하지 않습니다.
2m을 사용하는 이유는 미분을 하게 되면 공식이 단순해지기 때문에 일부러 넣는 것입니다.
W = W - 변화량
현재 위치에서 변화량을 계산하여 현재의 W에서 빼면 다음번 W의 위치가 나오게 됩니다.
convex 한 함수를 상상해 봤을 때 왼쪽 경사에 있을 때는 변화량이 음수가 되어서 W의 값이 증가하게 되고 convex함수의 오른쪽 경사에 있을 때는 변화량이 양수가 되어서 W의 값이 감소하게 됩니다. 결국 어느 위치에 있건 중앙에 있는 cost가 가장 적게 발생하는 최소 비용에 수렴하게 됩니다.
그렇다면 '변화량'은 어떻게 구할까요?
현재 위치에서 발생한 cost에 대해 미분을 하면 됩니다. 즉, Cost에 대해서 W로 미분을 하게 됩니다.
저희가 학교에서 배운 그래프에서는 x가 변할 때의 y 변화량을 계산하기 때문에 항상 x에 대해 미분을 했었죠.
공식의 앞에 붙어 있는 α(알파)는 중요하지 않습니다. 우리가 구한 변화량을 어느 정도로 반영할 것인지에 대한 상수일 뿐입니다.
최종적으로 완성된 알고리즘 수식을 여러 번 실행시키면 W값이 바뀌겠죠?
따라서, cost를 최소화시키는 w를 기계적으로 구할 수 있습니다.
이것이 Linear Regression 학습 과정의 핵심이라고 할 수 있습니다.
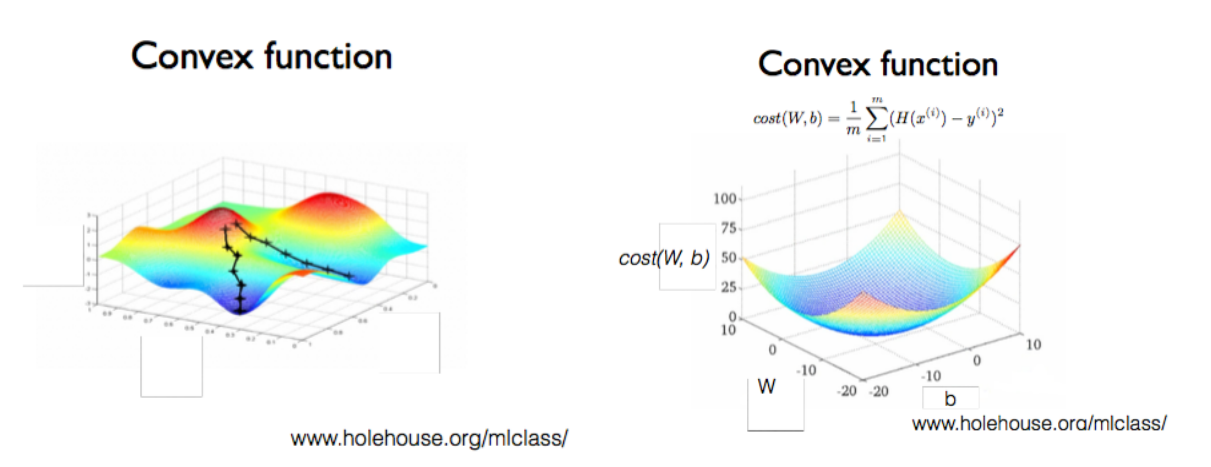
3차원으로 그려져 있는 그림입니다. 가로와 세로는 W와 b, 높이는 cost를 가리킵니다.
즉, W와 b의 값에 따른 cost를 표현하고 있습니다. cost 함수라고 얘기할 수 있겠죠.
우리가 만든 모델의 cost 함수가 왼쪽 그래프와 같은 형태로 표현된다면, 어디서 시작하는지에 따라 최저점에 도착할 수 있습니다. 따라서, cost함수는 왼쪽처럼 울퉁불퉁한 형태로 동작하지 않게 만들어야 합니다.
반드시 오른쪽 그래프와 같은 모습인 convex(오목) 함수 형태가 되도록 만들어야 합니다.
convex함수에서는 어느 점에서 시작하든 간에 항상 도착하는 점이 우리가 원하는 점입니다.
이런 경우에는 gradient descent에서 항상 답을 찾을 수 있습니다.
gradient descent 알고리즘은 convex(오목, 밥그릇) 형태에 대해서만 적용할 수 있기 때문에 이 사실은 매우 중요합니다.
'Main > Machine Learning' 카테고리의 다른 글
| [ML - lec 07] ML의 실용과 몇 가지 팁 (0) | 2022.03.13 |
|---|---|
| [ML - lec 06] Softmax Regression (Multinomial Logistic Regression) (0) | 2022.03.13 |
| [ML - lec 05] Logistic (Regression) Classification (0) | 2022.03.06 |
| [ML - lec 04] Multi-variable linear regression (0) | 2022.03.06 |
| [ML-분류] 앙상블 학습(Ensemble Learning) (0) | 2022.02.04 |




댓글